Combinatorial RNA
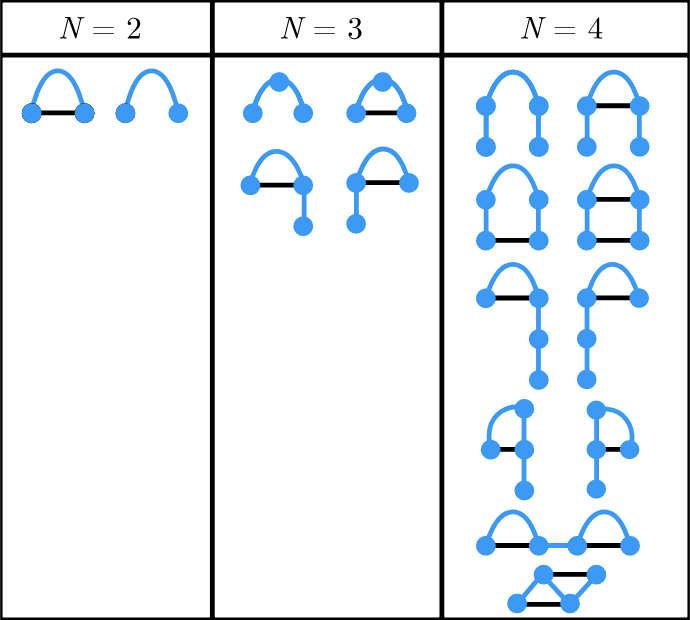
RNA molecules are long chains of different repeating units called bases , which can either fold and pair with any other base on the same molecule, or remain unpaired. For short RNA chains, the number of possible arrangements can be quickly enumerated by inspection. Which arrangement the RNA tends to fold into depends on its sequence of bases: given a sequence, every arrangement can be "scored", as some pairs are more likely to form stable bonds than others.
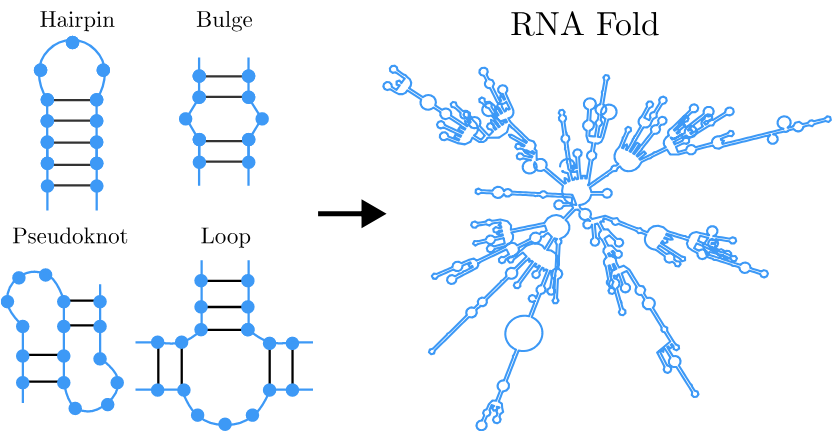
For biological RNAs, the typical length is greater than 100 bases. As with shorter lengths, the arrangement that the RNA folds into depends on its sequence, but the number of possible arrangements to consider is outrageously large, including many common structural motifs shown below.
For an RNA molecule consisting of N = 1 0 0 bases, there are n different arrangements which it can choose from.
How many digits are in
n
expressed in base
1
0
?
This section requires Javascript.
You are seeing this because something didn't load right. We suggest you, (a) try
refreshing the page, (b) enabling javascript if it is disabled on your browser and,
finally, (c)
loading the
non-javascript version of this page
. We're sorry about the hassle.
3 solutions
Log may be a bit inaccurate and its use looks cumbersome, print(len(str(R[100]))) is simpler, though takes more time.
Log in to reply
You are right, the formula I originally write although it is correct on paper, fail in some cases when implemented. For example print(1 + log(1000)/log(10)//1) returns 3 and no 4 as it should. Do you know why this is??
Log in to reply
Due to finite precison (usually 64 bits) of the hardware floating points. In hexadecimal instead of
log(1000) / log(10) = 3 we obtain
0x1.ba18a998fffap+2 / 0x1.26bb1bbb55516p+1 = 0x1.7ffffffffffffp+1
That is, just a bit less than 3.
This problem is an application of permutations .
Let's break down the steps required to count the number of arrangements. We'll have to
- Select the number of pairs k to consider.
- Select 2 k bases to form the k pairs out of.
- Partition the 2 k bases into k pairs, each of which have 2 bases.
For Step 1, we'll have to sum up all possible number of pairs, from 0 (a completely unpaired molecule of N bases) to N / 2 (every base is paired). So from this step, we'll just take some number k to stand for the number of base pairs we'll be considering for the later steps.
For Step 2 , we need to choose 2 k bases from the N total bases in the molecule to participate in the k base pairs. This is a pretty straightforward quantity that we can express using the binomial " N choose 2 k ":
( 2 k N ) = ( 2 k ) ! ( n − 2 k ) ! N ! .
For Step 3 , things get a bit more dicey. Since this is a partitioning problem, we seek to find the number of ways to put 2 k interchangeable bases into k pairs, so that each pair has exactly 2 bases in it. A good first guess might be to use the multinomial, something like this:
( 2 , . . . 2 N ) ,
where the number of 2 in the multinomial is k , the number of pairs we wish to form. This multinomial is equivalently stated using factorials as:
( 2 , . . . 2 N ) = 2 k ( 2 k ) ! ,
since 2 ! = 2 .
But we'd be way over-counting if we took this term as the number of ways of performing Step 3. If we use a straight up binomial, we're assuming an ordering on the pairs even though they don’t have one, the order of the pairs that we select don't matter when we're uniquely determining an RNA structure, so we are over-counting by a factor of the number of ways of arranging the k base pairs. So to correct for this factor, we can still use the multinomial but we also have to divide by a factor of k ! . So the number of ways of performing Step 3 is:
( 2 , . . . 2 N ) × k ! 1 = 2 k k ! ( 2 k ) ! .
Add 'em up
So combining Steps 2 and 3, we can figure out the number of arrangements for a given number of base pairs k :
n ( k ) = ( 2 k ) ! ( N − 2 k ) ! N ! 2 k ( 2 k ) ! k ! 1
As we mentioned for Step 1, we need to add up all the possible numbers of base pairs n , from 0 to N / 2 . Of course if N is odd, we don't want a fraction, so really we want the floor: ⌊ 2 N ⌋ .
n = 0 ∑ ⌊ 2 N ⌋ ( N − 2 k ) ! 2 k k ! N !
Now that we've got this function, we can just plug in the number of bases we're considering, N = 1 0 0 , to yield the number of arrangements. I did this with Mathematica. It's a really big number:

n ( 1 0 0 ) = 2 4 0 5 3 3 4 7 4 3 8 3 3 3 4 7 8 9 5 3 6 2 2 4 3 3 2 4 3 0 2 8 2 3 2 8 1 2 9 6 4 1 1 9 8 2 5 4 1 9 4 8 5 6 8 4 8 4 9 1 6 2 7 1 0 5 1 2 5 5 1 4 2 7 2 8 4 4 0 2 1 7 6
Which has 83 digits.
Side Note
For short RNA sequences, enumerating all the possible arrangements and scoring them using their sequence is practical. Given a sequence, if an A base pairs with a U base the score goes up by 1 , as with a C base pairing with a G base. Other "wobble" pairs like U and G add a somewhat lower number to the score.
But there's no way anyone is ever going to enumerate and score all of the arrangements for a N = 1 0 0 RNA molecule. Thanks to some enterprising work by a biologist named Ruth Nussinov in the late 1970s, we don't have to. Her algorithm uses dynamic programming to decrease the time requirements from combinatorial O ( n ! ) to low polynomial time O ( n 3 ) .
If all the solutions require programming I think a coding environment would be useful to have under the problem. After finding the recursion I got the rough approximation n(k)~(k/e)^(k/2) giving log(n(100))~(2-0.4342)*50~78
Log in to reply
You're right, Levente. I've added a coding environment to the problem. Cheers.
It's not clear to me what the algorithm from Ruth Nussinov does in polynomial time. It scores every sequence? To score every sequence you'd need to enumerate all of them. It scores a single sequence? That can be obv be done in a linear time
Log in to reply
Nussinov's algorithm scores the different arrangements as it goes, and only considered the highest scoring arrangement for a given sequence. It only ends up scoring order N 3 arrangements and is guaranteed to find the highest scoring arrangement, given one important caveat.
It takes advantage of a pattern in biological RNAs that I didn't mention in the problem: pairs are almost always nested . Bases "inside" of a pair will only pair with other bases inside. An example RNA is shown below, with the connectivity drawn with concentric (or nested) arcs:

This means if you can enumerate and score all the arrangements of a short subsequence and find the optimal one, that arrangement will remain the same even if you expand the subsequence. So the Nussinov algorithm scores short, easily enumerated subsequences, then expands one base at a time in both directions, only forming pairs which score highest. This nested quality of RNA arrangements makes this problem well suited to dynamic programming, which needs to be able to break the intractable problem into many simpler and independent sub-problems.
This is one of the focuses of a new chapter that's coming out in Brilliant's Computational Biology course in the next few days.
Blake
Log in to reply
Thanks, very interesting. Hence the purpose of the algorithm is finding the highest scoring sequences
If we have n nodes, the number of pairs that can be formed ranges from 0 to ⌊ 2 n ⌋ .
To place p pairs among n nodes can be done in ( n − 2 p ) ! 2 p p ! n ! ways.
For n=100, we sum this expression for p ranging from 0 to 50 and get
p = 0 ∑ 5 0 ( n − 2 p ) ! 2 p p ! n ! = 2 4 0 5 3 3 4 7 4 3 8 3 3 3 4 7 8 9 5 3 6 2 2 4 3 3 2 4 3 0 2 8 2 3 2 8 1 2 9 6 4 1 1 9 8 2 5 4 1 9 4 8 5 6 8 4 8 4 9 1 6 2 7 1 0 5 1 2 5 5 1 4 2 7 2 8 4 4 0 2 1 7 6
which has 8 3 digits.
See also Sloane's OEIS
Let's call R N the number of different arrangements of an RNA molecule consisting of N bases.
Consider the very first base of the chain, there are two possibilities for it:
If it's free, then the other bases can be arranged in R N − 1 different ways.
If it's paired, there are N − 1 possible couples for it and in each case, the remaining bases can be arranged in R N − 2 different ways.
We have a recurrence relation! starting whith R 1 = 1 and R 2 = 2 : R N = R N − 1 + ( N − 1 ) R N − 2
One could try here to find a closed form for the recurrence, but it is generally not easy to do so. I just wrote a little Python code to find R 1 0 0 = 2 4 0 5 3 3 4 7 4 3 8 3 3 3 4 7 8 9 5 3 6 2 2 4 3 3 2 4 3 0 2 8 2 3 2 8 1 2 9 6 4 1 1 9 8 2 5 4 1 9 4 8 5 6 8 4 8 4 9 1 6 2 7 1 0 5 1 2 5 5 1 4 2 7 2 8 4 4 0 2 1 7 6 that has 8 3 digits.