Efficient Archiving
A factory robot continually receives instructions. The table lists the five possible instructions, the frequencies with which they occur, and the bit strings used for archiving: The archiving code is developed in such a way that it can be coded and decoded unambiguously. For instance, the sequence "auto, op1, auto, check, op3" translates to the bit string Moreover, this code is designed to result in the shortest possible expected length. Convince yourself that, with the given frequencies, one can expect 2.28 bits of code per instruction.
Over the years, the frequencies of the instructions have changed gradually. The instructions are now used less often, and instead is used more frequently. A brilliant factory employee wonders if it might be more efficient to switch to a different bit string code.
To what percentage should the frequency of increase to warrant a change in the bit code for archiving?
Assume that the frequencies of remain equal to one another, and that the frequency of never changes. Give your answer as a percentage, rounded to the nearest integer.
The answer is 37.
This section requires Javascript.
You are seeing this because something didn't load right. We suggest you, (a) try
refreshing the page, (b) enabling javascript if it is disabled on your browser and,
finally, (c)
loading the
non-javascript version of this page
. We're sorry about the hassle.
Solution 1
The other possible coding schemes with the same order of frequencies are as follows:
Scheme II: instruction a u t o c h e c k o p 1 o p 2 o p 3 frequency x y z z z bit string 0 1 1 0 1 1 1 1 0 0 1 0 1 1 bit 3 bits 3 bits 3 bits 3 bits
Scheme III: instruction a u t o c h e c k o p 1 o p 2 o p 3 frequency x y z z z bit string 0 1 0 1 1 0 1 1 1 0 1 1 1 1 1 bit 2 bits 3 bits 4 bits 4 bits
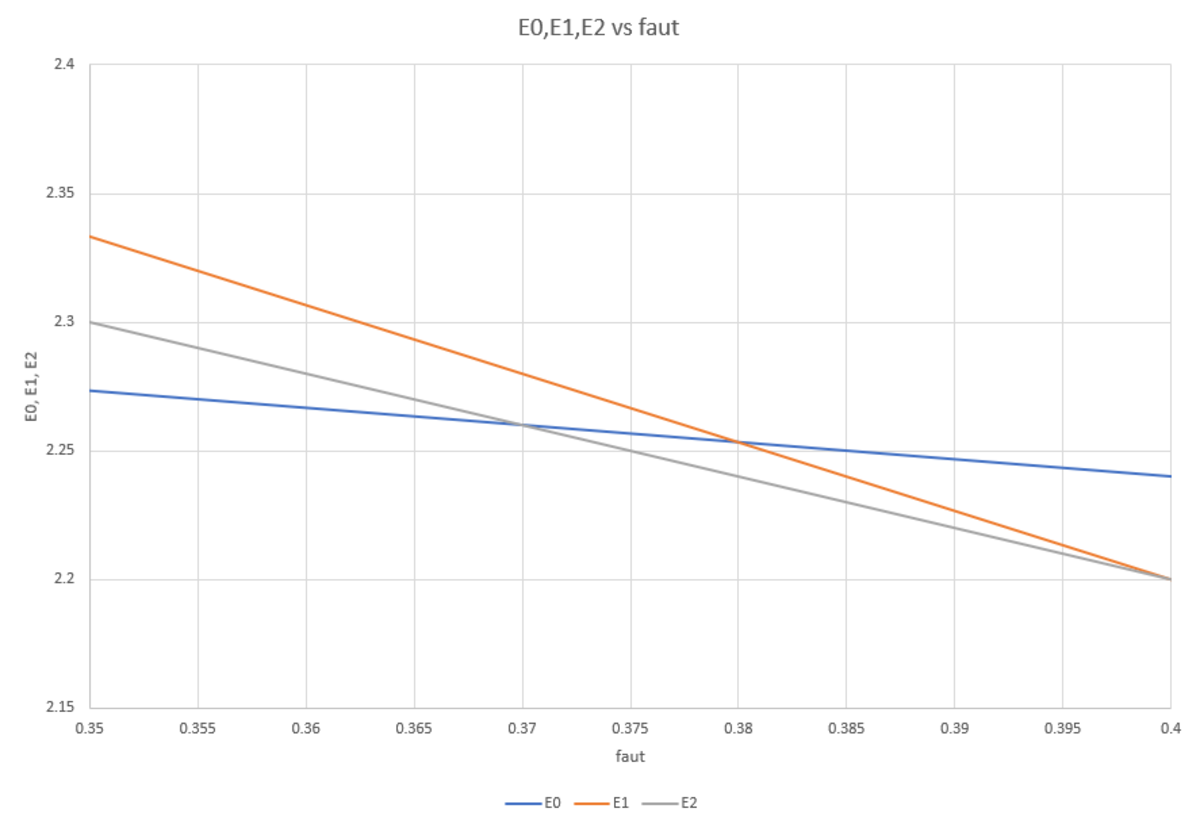
We have y = 0 . 2 4 , and z = 3 1 ( 0 . 7 6 − x ) ; the expected bit string length for each of the schemes is: ⎩ ⎪ ⎨ ⎪ ⎧ n I = 2 x + 2 y + 8 z = 3 1 ( 7 . 5 2 − 2 x ) n I I = x + 3 y + 9 z = 3 . 0 0 − 2 x n I I I = x + 2 y + 1 1 z = 3 1 ( 9 . 8 0 − 8 x ) for scheme I (current code) for scheme II for scheme III
Now n I I < n I iff x > 0 . 3 7 ; and n I I I < n I if x > 0 . 3 8 . Therefore it is efficient to switch to scheme II as soon as the percentage of a u t o increases beyond 3 7 % . (Note: for values over 4 0 % , it is more efficient to switch to scheme III.)
x n I n I I n I I I 3 4 % 2 . 2 8 0 2 . 3 2 0 2 . 3 6 0 3 5 % 2 . 2 7 3 2 . 3 0 2 . 3 3 3 3 6 % 2 . 2 6 7 2 . 2 8 0 2 . 3 0 7 3 7 % 2 . 2 6 0 2 . 2 6 0 2 . 2 8 0 3 8 % 2 . 2 5 3 2 . 2 4 0 2 . 2 5 3 3 9 % 2 . 2 4 7 2 . 2 2 0 2 . 2 2 7 4 0 % 2 . 2 4 0 2 . 2 0 0 2 . 2 0 0 4 1 % 2 . 2 3 3 2 . 1 8 0 2 . 1 7 3
Solution 2
The most efficient bit string code is generated by the Huffman algorithm . We will apply this algorithm to the original values and reconstruct the given bit code; but we also keep track of the conditions under which the algorithm changes.
This algorithm tells us to "lump together" the elements with the lowest frequencies, and to repeat this process until a coding "tree" is built. In our case, we start out with the following elements and frequencies: a u t o : 3 4 % + 3 δ ; c h e c k : 2 4 % ; o p 1 : 1 4 % − δ ; o p 2 : 1 4 % − δ ; o p 3 : 1 4 % − δ .
The first step of the algorithm combines the instructions o p 2 and o p 3 : a u t o : 3 4 % + 3 δ ; c h e c k : 2 4 % ; o p 1 : 1 4 % − δ ; [ o p 2 , o p 3 ] : 2 8 % − 2 δ . Second step: Now the lowest frequencies are those of c h e c k and o p 1 , so they will be combined next. However , this choice will change if the combined frequency of o p 2 and o p 3 becomes less than 24\%. The Huffman code will change its behavior if δ > 2 . a u t o : 3 4 % + 3 δ ; [ c h e c k , o p 1 ] : 3 8 % − δ ; [ o p 2 , o p 3 ] : 2 8 % − 2 δ .
Third step: Now the lowest frequencies are those of a u t o and [ o p 2 , o p 3 ] . Therefore they will be combined next. However , this choice changes if the frequency of a u t o becomes greater than that of [ c h e c k , o p 1 ] . We solve 3 4 + 3 δ = 3 8 − δ to find that this will be the case when δ = 1 . The Huffman code will change its behavior if δ > 1 . [ c h e c k , o p 1 ] : 3 8 % − δ ; [ a u t o , [ o p 2 , o p 3 ] ] : 6 2 % + δ .
Fourth step: The last two elements are combined. [ [ a u t o , [ o p 2 , o p 3 ] ] , [ c h e c k , o p 1 ] ] : 1 0 0 % . From this nested list one can read off the bit code: register "0" for the left element, "1" for the right element.
In the analysis above, we saw that the Huffman code changes first when δ becomes greater than one; this means that the frequency of a u t o has become 3 7 % . The result will be [ a u t o , [ [ o p 2 , o p 3 ] , [ c h e c k , o p 1 ] ] ] . This corresponds to what we called "Scheme II" under Solution 1 above.
Further analysis
Here is a graphical analysis of bit codes for an alphabet with a symbol of frequency x , a symbol of frequency y , and three symbols of equal frequency 3 1 z .
The Roman numerals represent the various optimal codes:
Code I : x , y , z 1 : 2 bits; z 2 , z 3 : 3 bits.
Code II : x : 1 bit; y , z 1 , z 2 , z 3 : 3 bits.
Code III : x : 1 bit; y : 2 bits; z 1 : 3 bits; z 2 , z 3 : 4 bits.
Code IV : x , z 1 , z 2 : 2 bits; y , z 3 : 3 bits.
Code V : z 1 , z 2 , z 3 ; 2 bits; x , y : 3 bits.
(In codes II , III , _ IV , swap x and y for the right side of the diagram.)
The expected number of bits per character may be read off using the red lines/numerals.
The following detail shows the particular situation of this problem, where the frequency of x increases from 3 4 % , while the frequency of y remains constant at 2 4 % :
Follow the purple arrow to see how with increasing x , the code changes from I to II to III .