Infinite Xor Problem
Let \(m>n>d\) be positive naturals and \(X=\langle x_{i}\mid i<m\rangle\in\{0,1\}^m\). Define \(f_{X}:[m]^{n}\longrightarrow \{0,1\}\) via \(f_{X}(i_{0},i_{1},\ldots,i_{n-1})=1\) exactly in case \(|\{j<m\mid x_{i_{j}}=1\}|=d\). Note, that the map \(X\in\{0,1\}^{m}\mapsto f_{X}\) is not necessarily injective.
Now assume one has access to just . How can one recover the list of all possible sequences via computational means, such that ? Theoretically one can go through (via lexical ordering) the list of all elements and compute each and check if . But this will have a long average running time.
Construct an algorithm, which satisfies and for all and . Further let be the total number of calls to the oracle during the execution of and
which is effectively the average running time. Find an algorithm, , such that is minimised for all , if this is at all possible.
There is a more relaxed version of this problem in which , and is a fixed value. This version may be more likely to have a polynomial time solution algorithm, or with an algorithm such that .
A basic flowchart of how the solution algorithm should function in practice:
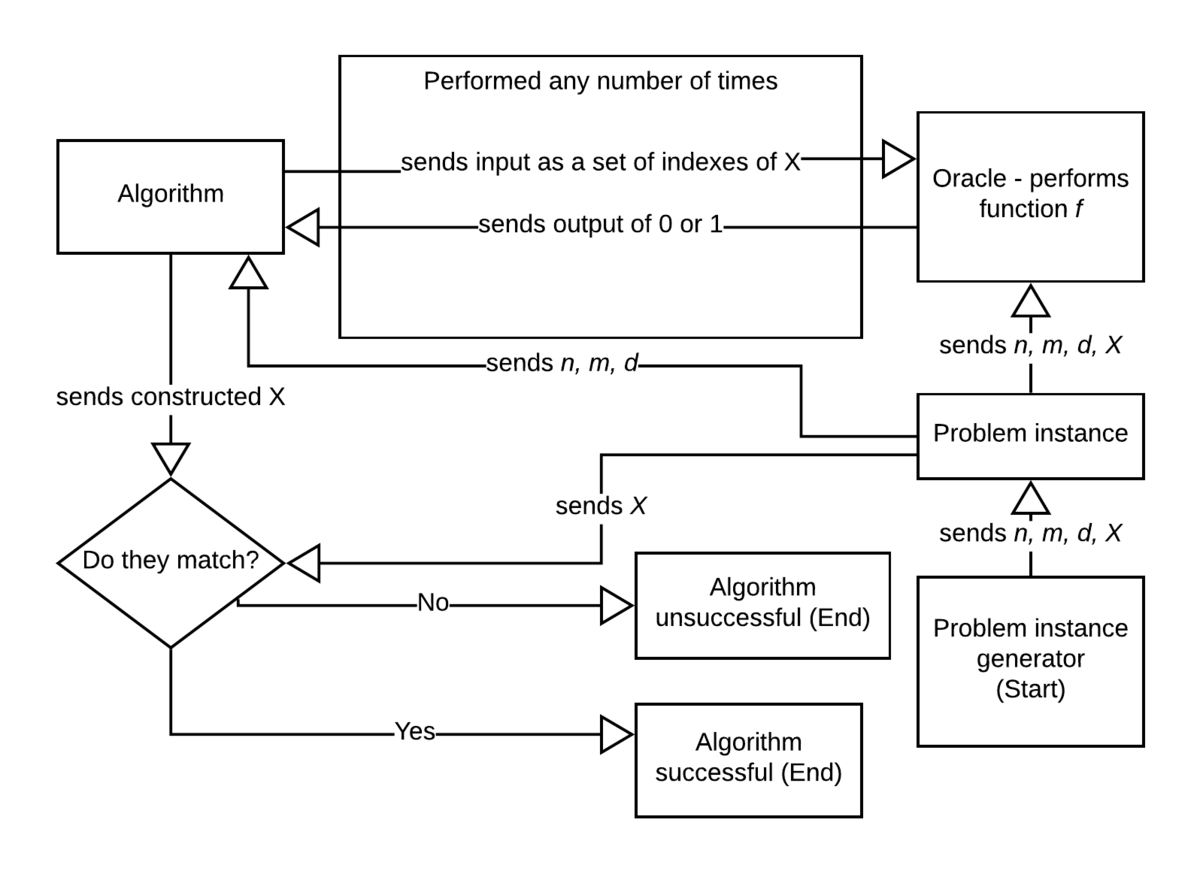
An example procedure:
The problem instance generator decides values . This information is sent to the oracle who can perform function , and the values of , and are sent to the algorithm.
The algorithm decides to call f(0, 1) to which the oracle returns 1 as it knows exactly one of and is 1 and the rest are 0. Then, the algorithm calls f(0, 2) which returns 1 and f(1, 2) which returns 0. Since and match and both are different to , the algorithm can determine that or . The algorithm sends both, and they compared with the sent by the problem instance generator. Since there is a match, the algorithm has done a successful run for one combination of for values .
Credit to R Mathe for helping rewrite and improve this.
Note by
Darcy Morgan
3 years ago
Easy Math Editor
This discussion board is a place to discuss our Daily Challenges and the math and science related to those challenges. Explanations are more than just a solution — they should explain the steps and thinking strategies that you used to obtain the solution. Comments should further the discussion of math and science.
When posting on Brilliant:
*italics*or_italics_**bold**or__bold__paragraph 1
paragraph 2
[example link](https://brilliant.org)> This is a quote# I indented these lines # 4 spaces, and now they show # up as a code block. print "hello world"\(...\)or\[...\]to ensure proper formatting.2 \times 32^{34}a_{i-1}\frac{2}{3}\sqrt{2}\sum_{i=1}^3\sin \theta\boxed{123}Comments
Unfortunately, I can't help you. Sorry !
Log in to reply
That's okay! It's still reassuring to know that my idea is worth your time.
Please clearly and formally redo the first set of bullet points and the paragraph before this. Your text is both mathematically and grammatically incomprehensible. For example
Log in to reply
Thanks for the feedback. While they are admittedly obvious mistakes now that I look back, I haven't had experience writing "mathematically" like this. I've rewritten it and taken away the example case to try and make it read smoother. Please let me know if it makes sense to you now or if I missed something else.
It seems important to keep both versions of the problem as the first version seems more likely to have a polynomial-time algorithm.
Log in to reply
Your current formulation is a lot clearer. Having both versions is absolutely fine. Remaining issues:
Log in to reply
Yes, I should be using sequences, I didn't realise there were angled brackets for that.
I've added a diagram and a more complete example to describe what I expect as a solution. What I am interested in is the lowest average case number of calls to f a successful algorithm needs and how it is affected by changing m, n and d.
Log in to reply
Okay, I think I understand. Your original description prove that it is possible to determine all values of X is thus thoroughly misleading. The known inputs are m, n, d, the hidden inputs is the sequence X itself. Moreover, the function is NOT to be executed as f(x0,x1,…,xm−1), as per the original description, but rather as f(i0,i1,…,in−1) where i0,i1,…,in−1∈{0,1,2,…,m−1} are distinct indices. The problem is thus:
Let m>n>d be positive naturals and X=⟨xi∣i<m⟩∈{0,1}m. Define fX:[m]n⟶{0,1} via fX(i0,i1,…,in−1)=1 exactly in case ∣{j<m∣xij=1}∣=d. Note, that the map X∈{0,1}m↦fX is not necessarily injective.
Now assume one has access to just m,n,d,f. How can one recover the list of all possible sequences X via computational means, such that fX=f? Theoretically one can go through (via lexical ordering) the list of all elements Y∈{0,1}m and compute each fY and check if fY=f. But this will have a long average running time.
Construct an algorithm, A(⋅,⋅,⋅,⋅) which satisfies A(m,n,d,f)⊆{0,1}m and ∀X∈{0,1}m: X∈A(m,n,d,f)⇔fX=f for all m>n>d and f:[m]n⟶{0,1}. Further let T(m,n,d,f) be the total number of calls to the oracle f during the execution of A(m,n,d,f) and
T(m,n,d):=2m1X∈{0,1}m∑T(m,n,d,fX)
which is effectively the average running time. Find an algorithm, A(⋅,⋅,⋅,⋅), such that T(m,n,d) is minimised for all m,n,d, if this is at all possible.
Note: [m]n=[{0,1,2,…,m−1}]n={A⊆{0,1,2,…,m−1}∣∣A∣=n}, thus ∣[m]n∣=([m]lmn) elements.
Log in to reply
Very well written, and a tremendous thank you for rewriting it in an easier to understand format.
Now that I think about it, the algorithm might not need to compute all values of X to find the average to a reasonable degree of accuracy, but yes that is why computing all of them seemed important at the time of writing.
A concrete purpose of this problem is investigating if it is possible that ∃m ∃n ∃d ∀X:T(m,n,d)<∣X∣ or the more loose condition ∃m ∃n ∃d ∃X:T(m,n,d,f)<∣X∣ which could lead to a multiple compression algorithm where n, m and d are commonly known and the calls to fX as decided by the algorithm is stored inside a new X, which can be reduced using the algorithm again and so on.
Thanks again for all of your help.
Log in to reply
not a problem. Do you want to compute the average over all f ie
T(m,n,d):=2∣[m]n∣1f∈{0,1}[m]n∑T(m,n,d,f)
or over all X ie
T(m,n,d):=2m1X∈{0,1}m∑T(m,n,d,fX)
I came up with an algorithm. I’ll post it later. Not sure if it’s the most efficient, tho’.
Log in to reply
Over all f. The way I understand it currently, the average over all X doesn't sound useful.
Log in to reply
There are two possibilities:
the problem is a kind of d-SAT problem: one is given (coded via f) knowledge of m propositions and when for every n-Tuple exactly d are true, and wishes to prove the existence of a model, satisfying these conditions. Then we need to compute the average over all f.
the problem is of the form: a hidden X is given and we only see fX. We are to compute a possible value of X. Then one needs to compute the average over all X.
My first algorithm so far is really inefficient: T(m,n,d,f)=m!/(m−n)!∼mn. If n,d are fixed then this is polynomial in ∣X∣. If not, then this is exponential time (or worse!). The algorithm I employ is a simple recursion and doesn’t dynamically react to partial results, which is probably why it is not very fast. I need to think about this further.
Whilst your problem isn’t exactly 3-SAT, there seem to be connections, and the latter is NP-hard, as far as I recall, so finding an efficient algorithm may be doomed. On the other hand, I’ve heard that replacing NP-problems by randomised counterparts may make more efficient algorithms possible.
Do you really want the algorithm to compute all or to just find any one value of X?