How many words can be made from these letters?
Computer Science
Level
4
Using the letters in the string,
skylarowensavelandandstevebaker
, how many words from
this list
can you make which are at least 3 letters long? (Case matters)
The answer is 7025.
This section requires Javascript.
You are seeing this because something didn't load right. We suggest you, (a) try
refreshing the page, (b) enabling javascript if it is disabled on your browser and,
finally, (c)
loading the
non-javascript version of this page
. We're sorry about the hassle.
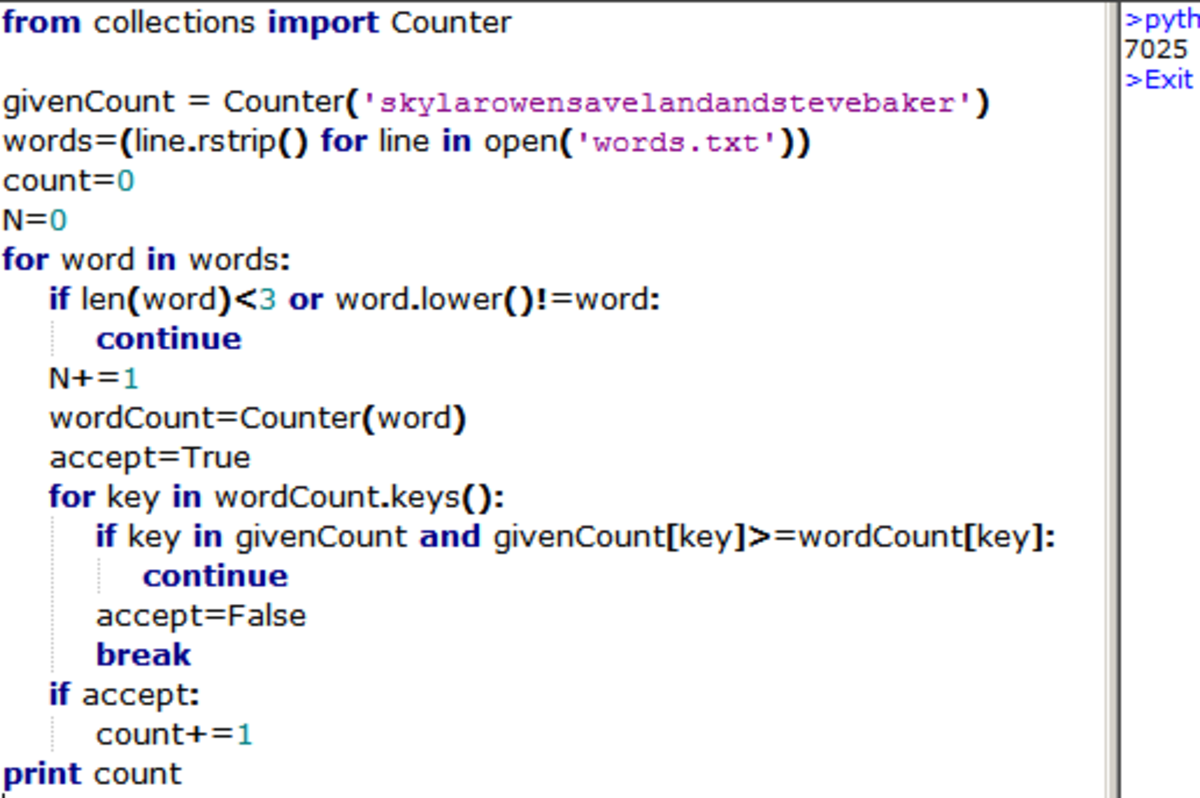
There is a python script that does the job here . However, I think the filtering can be improved upon. I'm curious to see what other people can come up with.
The number of calls to
filter_wordshas a bound of about 250,000. So, that's high but constant,O(235674). Withinfilter_words, however, we see that the calls tocountwith this code grows somewhat aggressively .. is thatO(log n)?:Here is the profile of the given problem:
Compare that with:
Not bad. But, I bet you can do better.