Is this a good spam filter?

Rakesh’s spam filter predicts whether or not an email is spam. It is 98% accurate at identifying either type of email, and he knows that 1% of the emails sent to him are spam.
Which is more likely to be true if he receives an email that his filter predicts is spam?
This section requires Javascript.
You are seeing this because something didn't load right. We suggest you, (a) try
refreshing the page, (b) enabling javascript if it is disabled on your browser and,
finally, (c)
loading the
non-javascript version of this page
. We're sorry about the hassle.
12 solutions
Moderator note:
First note the problem does state the accuracy applies to "either kind of email"; so 98% of both spam and non-spam will be correctly identified, 2% of both spam and non-spam will be incorrectly identified.
The most common theme in the incorrect answers below is interpreting the question as
Given an email, what is the probability it is identified correctly?
when the question is actually:
Given an email identified as spam, what is the probability that it is spam?
This is a much different question. If you're still having trouble, we have multiple places on Brilliant that can help:
Conditional Probability Misconceptions quiz
Really helps to visualise the solution.
Could you also say the ratio of inaccuracy vs accuracy is 2:1? And skip the second part of the solution?
In Medical testing this analysis occurs all the time.
Using medical terms, The probability that a known Spam Email is detected as Spam is called the Sensitivity of the test.
The probability that a known non-Spam Email is deemed non-Spam is called the Specificity of the test. In the question Sens and Spec are the same (98%) but in real life they almost never are!
The converse - the probability that a Positive test result actually does represent a Positive is called the Positive Predictive Value (PPV) of a test.
And of course there is an NPV!
This underlies which screening programmes (eg Pap/cervical smears) are set up for the population.
This is a nice example that shows how accuracy usually isn't the proper metric for performance in classification problems. Imagine we had an algorithm that always predicts that email is non-spam - then accuracy of that algorithm in this case would be 9 9 %, greater than than the Rakesh's algorithm! Instead, precision and recall are commonly used to give better sense of algorithm's performance. Precision is the percent of spam emails marked as spam, and it is calculated as the ratio between true positives (spam marked as spam) and all the positives (all emais marked as spams). On the other hand, recall is the percent of emails marked as spam which are actually spam, and it is calculated as the ratio between true positives and true positives plus false negatives (all spam emails). Another metric which is pretty useful because it combines precision and recall is F1 score. These three metrics are widely use in Machine Learning where they can point out on which class your algorithm is not doing a really good job, so you know what part of the algorithm you should improve.
Shouldn't 2% of 10000 be 200 instead of 198 and 1% be 100 instead of 98? or am I really not seeing something important. Not really good with these lateral thinking problems.
Log in to reply
The percentages have been taken already at the start of the problem. We take them out of 100.
However, we have two ways of thinking of a set of 100, so we set up a 10000 x 10000 grid where we can compare the two categories. Note that the percentages are still identical; the slice that's 2 wide and 100 tall represents 2% of 10000, for instance.
The question asked "Which scenario is more likely to be true if he receives an email his filter marks as spam? Spam or not spam?"
For a given email he has a 98% chance of picking correctly. 98% chance to identify spam as spam and 98% chance to identify 'not spam' as 'not spam'.
The fact that he knows only 1% of his total emails are spam is irrelevant. Even if 99% of his email was spam, the filter still has a 98% chance of identifying it correctly for an individual email.
The question does not ask 'out of x emails, how many are identified correctly' or any thing like that. It states clearly that 'if he receives an email his filter has marked as spam' would it more likely be spam or not spam? If you take his first statement that the filter is 98% accurate as true, then doesn't that mean a 98% chance the filter is correct - and the email is more likely to be spam.
Perhaps the question should be framed differently?
Log in to reply
The answer would've been 98% if it asked for 'if you know that the email is spam, how likely is it that the filter marks it as spam?'
But the question doesn't ask for that.
Since there are more not-spam than spam emails, if you picked a random email, it would be more likely that it is not spam.
0.98% of all emails are spam and marked as spam, while 1.98% of all emails are not spam but marked as spam.
The filter takes 2% of all normal emails and 98% of all spam emails to be marked as spam.
Due to the high volume of non-spam emails, a small amount of it is less than a large amount of a smaller quantity.
In other words, 2% of 99% is greater than 98% of 2%.
Log in to reply
I think everyone is answering different questions. I agree with your statement that if you picked a random unfiltered email, it would be more likely that it is not spam. But that was not the question. The question clearly states that the email was flagged as spam. The volume of non-spam email has no bearing on the accuracy of his filter, which is stated to be 98%.
Suppose Rakesh has just emptied his mail box. 1 new email arrives. His filter flags it as spam. What is the likelyhood that this email truly is spam if his filter really is 98% accurate?
Another point of view: look at 100 emails that have been flagged by his filter. 98 should be spam and 2 should be non-spam.
The question is about an email that has been flagged by his filter, not about the overall mix of spam vs non-spam that he receives.
Log in to reply
@Garrett Roy – The mix of spam and non-spam is quite relevant to how accurate the filter is.
If your frequency of non-spam is higher than spam, then you have more chances to inaccurately identify non-spam as spam.
The problem states it is flagged as spam, which means on the chart in this answer, you're only worrying about the two sectors marked in purple (spam that is accurately marked spam, non-spam that is inaccurately spam).
Log in to reply
@Jason Dyer – Quoting from my previous reply: "Suppose Rakesh has just emptied his mail box. 1 new email arrives. His filter flags it as spam. What is the likelyhood that this email truly is spam if his filter really is 98% accurate?"
If any given email that has been marked as spam by the filter is more than likely not spam, then the accuracy of his filter is at best less than 50%.
Are you all looking for statistical prediction based on the analysis of a certain volume of email being spam vs not spam or are you looking at the probability of any single given email being filtered incorrectly by his 98% accurate filter?
Log in to reply
@Garrett Roy – Not really mixing in the discussion, but the amount of email allready in the inbox or if it's just been emptied is not relevant. This process is 'memoryless', so it doesn't look at the amount of email allready in the inbox. I really agree with @Jason Dyer in this one.
Log in to reply
@Peter van der Linden – Agreed, the amount of email is irrelevant. Also agreed that the process is 'memoryless', meaning that prior results aren't part of the question. Flipping a coin is 'memoryless'. If I flip a coin (all physics being equal) there is a 50/50 chance of heads vs tails. If I flip it again, the odds are still 50/50. When I prepare to flip the coin for the 49th time the odds of heads vs tails is still 50/50. IF i have a 98% accurate filter for the email, dosn't that mean that there is a 98% chance it will correctly identify the email as spam or not spam for any given email? I don't care what the 50 emails before or after are, I am only looking at the results of the one email currently being filtered.
Log in to reply
@Garrett Roy – What, I think, you are missing is the very nature of accuracy as a metric of performance. Accuracy is very dependent on the ratio between positives and negatives (in this case let positives be spam emails, and negatives non-spam emails). Because accuracy is defined as the fraction of correctly classified emails, if you have a lot of non-spam emails, then your accuracy metric will heavily depend on them. Just to illustrate my point, say that Rakesh made another, much simpler algorithm which always predicts email to be non-spam. Then, because of much higher frequency of non-spam emails that algorithm would have accuracy of 99%! And now if an email arrives, and it is spam, the classifier would have 0 chance to correctly classify it as spam, even though it has such a high accuracy rate. That's why accuracy isn't the optimal metric in the classification problems where there's no balance between the frequencies among classes. I encourage you to read my comment on @Jason Dyer solution where I've discussed about more insightful metrics.
Log in to reply
@Uros Stojkovic – i understand the point about accuracy and I did read your other post. i guess my biggest sticking point with all of this is that everyone seems to be ignoring large portions of the data such as all of the emails that were successfully categorized. When reading your comment I get the impression that you think the question should be phrased differently as well since you refer to several different metrics that might give better measurements.
Log in to reply
@Garrett Roy – What exactly do you mean by "everyone seems to be ignoring large portions of the data such as all of the emails that were successfully categorized"? Algorithm can and is performing very differently on different classes. I don't think that question should be rephrased because, as I said in my comment, it serves as a nice example of flaws of accuracy as a metric, it breaks the perception that algorithm has to be equally "accurate" when dealing with different classes. So the question is fine, as well as the answer, although it may be counter-intuitive for some people.
@Garrett Roy – It's pretty specific: "can predict whether or not an email is spam with 98% accuracy." You hand the algorithm an email, it tells whether or not it is spam with 98% accuracy.
Another way to think about it is to imagine that the algorithm exists, but for whatever reason, your email box gets no spam at all (you managed to stay off internet commerce, intrusive e-cookies, etc). Even given this, the algorithm will sometimes indicate an email that you hand it is spam. Given a lot of emails, quite a few will be identified as spam. Now toss in a handful of real-spam messages, less than the number of real messages incorrectly identified as spam. It still will then be more likely that a spam-identified message will be one of the real ones. Clearly, then, the spam/non-spam ratio makes a difference.
Log in to reply
@Jason Dyer – I did not enterpret the question to be about the spam/non-spam ratio in his spam folder. I enterpreted the question to be about whether or not the messages were being marked correctly over all. I'm seeing a lot of the solutions seeming to ignore the number of emails that were normal and marked normal as well as those that were normal and marked spam. What if all of the inaccuracies were in the other direction - all of the errors were spam mail marked as normal? I don't see any solutions that take this in to account.
Excellent solution - easy to follow, covers everything and is not overlong.
It should say "its precision is 98%" and not mention accuracy (completely different concepts!!!).
Actually, this is wrong. Saying accuracy you cannot assume "I'm wrong on the spam class". Accuracy is a general measure and not a class oriented measure. However the accounting is correct.
Agree with @P A . There is an ambiguity of the term "accurate". Accurate in what:
- in selecting a correct type from all mail (then the error is 2%)
- in selecting a real spam mail from what it's considered as spam (then the error is 0.002%)
Very Bayes-ian.
I think there are too many out of work mathematicians looking for a math problem that isn't here. We need more engineers in here. It doesn't matter if 1% of email is spam or not. This is like the trick question "Julie flipped a coin 10 times and it came up heads the first 9 times. What is the probability of it being heads on the 10th flip?"
The way the question is worded is simply "is it more likely that the spam filter is correct or incorrect?" We are given that the spam filter is accurate 98% of the time. For every 100 emails, it is accurate 98 times. We don't need a pencil for this one, but perhaps someone to reword the question.
Log in to reply
Saying that it doesn't matter if 1% of mails are spam is wrong, because it does. If it was 3% instead of 1%, the answer would've been the other way round.
Log in to reply
If the spam filter is correct 98% of the time, it's right 98% of the time. Whether 50/100 emails or 1/100 emails are spam, it's still right 98% of the time and it is still analyzing one email with a 98% history of being correct.. So you still have to take the question as it is stated: is it more likely that the filter is correct or incorrect? Well, at 98% versus 2% ... I'm putting my bet on the 98%. Wouldn't you?
Log in to reply
@Mike Walker – Ok, look at it this way. We are given just one mail, plain and simple. We do not know whether or not it is spam, and we do not know the result obtained after running the filter on it either. No assumptions about anything.
Now, the accuracy of the filter = 98% means, as you said, its right 98% of the times. But we don't know what "right" means, in the context of this mail. It depends on whether or not the mail is actually a spam, and there is a probability associated to whether or not the mail is an actual spam.
Log in to reply
@Pratik Shastri – We know the context of that email because the only context we're concerned with is if it's spam or not, which the filter has flagged with 98% certainty.
Log in to reply
@Nick Combs – Given that the mail is spam, the chance that the filter says its a spam is 98%.
Given that the filter says its spam, the chance that the mail is a spam is not 98%.
There's a difference b/w the two.
Just wondering if the question (as currently worded) takes for granted that the accuracy (0.98) and its complement (0.02 = 1 - 0.98) are distributed equally across the 'spam' and 'not spam' categories. Doesn't really matter too much here, but thought this might cause confusion for some.
Example: If you assume (generously) that the filter always tags spam as spam, the P(spam, +) = 0.01 = 0.01 * 1. By extension of our 98% accuracy condition, this must mean P(not spam, -) = 0.97 and P(not spam, +) = 0.02. Note that the conclusion (a comparison of the conditional probabilities) isn't different (i.e., 0.02 > 0.01, more likely not spam), but the computation might be (ever so slightly). Compare this with the assumption taken in the solutions provided here (i.e., 0.0198 > 0.0098).
So ur saying all spam is not spam only 2%!!
I understand that, but when why is it marked as incorrect if you answer "The email is not spam"?
Log in to reply
it's not marked as incorrect
Log in to reply
I clicked that and it said incorrect... weird. When I do it now it says correct...
Excellent Solution!!! Simple yet Elegant!!!
Log in to reply
Only if 100% of emails are spam.
If the actual percentage of emails that aren't spam is less that this then the solution you are proposing is incorrect.
Log in to reply
I feel like you might be misreading the if-then statement.
It states "if it is identified as spam". We are indeed only considering the spam-identified emails.
This came up last week, too - we had an if-then statement with cards where some people wanted to read the statement backwards. Here, we are only considering the second part of the statement after presuming the hypothesis (that we are dealing with something identified as spam) is true.
Log in to reply
@Jason Dyer – if it is identified as spam, then the 98 percent of the 2 percent. Seems you really need to review your question texts
Log in to reply
@Glenn Matheson – yupp,even I interpreted the question in this way that 98% of the times the filter is accurate,which is likely to have predicted the spam mail correctly!!!
Ok, maybe this question is worded poorly. For any given email arriving, the spam filter predicts its nature with 98% accuracy. For any given email identified as spam, there is a 98% chance it is spam. Therefore, "if he receives an email that his filter predicts is spam" it is spam 98% of the time, which is "more likely to be true" than false. Just because false positives outnumber actual positives doesn't mean that for any given message there is anything other than a 98% chance of a correct result. That given message coming in is spam with 98% accuracy. Period.
Log in to reply
Not quite. Note that the problem isn't asking "What is the probability that the filter accurately classified this email?". If that was the question, then the answer is indeed 98%.
The question is "Given that the email was filtered as spam, what is the probability that it is indeed spam". This is a very common Conditional Probability Misconception .
Think about it this way, if 0% of the email that Rakesh receives is spam, then any email that is predicted as spam by the filter would be wrongly identified since we know that it is not spam. As such, "0% of the emails predicted as spam are actually spam". In this problem, the (relative) probabilities are important.
Log in to reply
I understand the problem that you are solving. It's not the problem stated in the question as written.
Log in to reply
@Christopher Cornette – The question (as currently stated) is
Which is more likely to be true if he receives an email that his filter predicts is spam?
In what way is it not similar to
Given that the email was filtered as spam, what is the probability that it is indeed spam?
The rough conversion is "Given that the email was filtered as spam" <-> "he receives an email that his filter predicts is spam" and "what is the probability that it is indeed spam" <-> "Which is more likely to be true".
In what way is it similar to
What is the probability that the filter accurately classified this email?
I am interested in hearing how you arrived at version so that we can clarify the problem for others.
Log in to reply
@Calvin Lin – Which is more likely to be true if he receives an email that his filter predicts is spam? = if he receives an email his filter predicts is spam, is that more or less likely to be true = if he receives an email that is classified as spam, is it more or less likely that his filter was accurate.
Log in to reply
@Christopher Cornette – I see we agree on "if he receives an email his filter predicts is spam".
I disagree with "is that more or less likely to be true (that the email is actually spam or not spam)" = "is it more or less likely that his filter was accurate". I added the words in parenthesis, which reflect the answer options. I am not sure where you got "that his filter was accurate" from. Can you elaborate on that choice?
If the answer options were a choice between "The filter is accurate" and "The filter is inaccurate", then I would agree that the more likely option is "The filter is accurate".
Log in to reply
@Calvin Lin – if the spam filtered message = spam (true), the filter was accurate. If it was not spam (false), the filter was not accurate. See above regarding the "either type of message" statement. Not sure why that is confusing.
Log in to reply
@Christopher Cornette – As mentioned to your deleted comment, there is where we disagree about what it means for the filter to be accurate.
We are taking very different prior conditioning. IE I am using "If the email is of type A, then the filter says it is of type A 98% of the time.", whereas you are using "If the email filter says it is of type A, then the email is of type A 98% of the time".
Thanks, let me think about how the problem statement can be clarified to avoid this misconception.
@Calvin Lin – I would also take major issue with "It is 98% accurate at identifying either type of email". It is not 98% accurate at identifying spam. It identifies spam with ~1/3 accuracy. It is 98% accurate at identifying what is not spam though.
One way of thinking about this problem is that the spam predictor isn't a very good algorithm, since if it simply predicted that the email wasn't spam 100% of the time, it would have a 99% accuracy rate rather than a 98% accuracy rate.
Exactly. I interpreted the question as "Given an email, what is the probability it is identified correctly?", since the question had stated, "it is 98% accurate at identifying EITHER KIND OF MAIL". Meaning it is 98% accurate at identifying 98% of spam as actual spam, and 98% of normal emails are normal emails. Maybe I had this misunderstanding because I'm bilingual? I'm not sure if that has something to do with my failure to grasp word problems like this. This isn't the first time this sort of thing has happened to be by the way.
Let x be the total number of Rakesh's e-mails.
If 2 % of 9 9 % of Rakesh's good e-mails are erroneously marked as spam, the number of good e-mails in Rakesh's spam folder is 0 . 0 2 ⋅ 0 . 9 9 ⋅ x = 0 . 0 1 9 8 x .
If 9 8 % of 1 % of Rakesh's spam e-mails are correctly marked as spam, the number of spam in Rakesh's spam folder is 0 . 9 8 ⋅ 0 . 0 1 ⋅ x = 0 . 0 0 9 8 x .
Since 0 . 0 1 9 8 x > 0 . 0 0 9 8 x for all positive values of x , there are more good e-mails than spam in Rakesh's spam folder.
I like the way you are using Bayes' theorem implicitly. In my opinion this is the way to teach conditional probability - lots of examples first to build up the students' intuition, and only later introduce the formalism.
Thank you for actually putting your answer into equation format. I suck at math, so for people like me, it's hard to understand the solution in words. It's really helpful to have a math problem I can work through.
For some reason everyone is assuming that the 2% error is good email marked as spam. What happens if the 2% error is in the other direction - the incorrectly categorized emails are spam but marked as good?
Log in to reply
Both are considered in my solution, although the 2% e-mails that are spam but marked as good is viewed instead as the 98% of spam that are correctly marked as spam.
I like your conclusion about the ratio of spam letters vs. false positives in the spam folder . Because I failed to understand the initial question .
P(SPAM|filtered) = P(SPAM) * P(filtered|SPAM) / P(filtered) = 0.01 * 0.98 / 0.02
P(NOTSPAM|filtered) = P(NOTSPAM) * P(filtered|NOTSPAM) / P(filtered) = 0.99 * 0.02 / 0.02
0.01 * 0.98 < 0.99 * 0.02
P(SPAM|filtered) < P(NOTSPAM|filtered)
The only concern I have is that 98% accuracy doesn't tell us that
P(filtered|SPAM)
= 0.98 and
P(filtered|NOTSPAM) = 0.02
It only tells us that
(true-positive + true-negative) / all trials = 0.98
Log in to reply
That is correct, accuracy = 9 8 % tells us ( true-positive + true-negative ) / all trials = 0 . 9 8 and nothing more.
But based on this assumption, it is possible to arrive at the desired answer. ( true positive / all trials ) is basically just P ( marked_spam ∣ SPAM ) × P ( SPAM ) .
Similarly ( true negative / all trials ) is P ( marked_notspam ∣ NOTSPAM ) × P ( NOTSPAM ) . Therefore we deduce that
P ( marked_spam ∣ SPAM ) × P ( SPAM ) + P ( marked_notspam ∣ NOTSPAM ) × P ( NOTSPAM ) ⟹ P ( marked_spam ∣ SPAM ) × P ( SPAM ) + [ 1 − P ( marked_spam ∣ NOTSPAM ) ] × P ( NOTSPAM ) ⟹ P ( marked_spam ∣ SPAM ) × P ( SPAM ) − P ( marked_spam ∣ NOTSPAM ) × P ( NOTSPAM ) = 0 . 9 8 = 0 . 9 8 = 0 . 9 8 − P ( NOTSPAM ) ( 1 )
We are to compare P ( SPAM ∣ marked_spam ) and P ( NOTSPAM ∣ marked_spam ) = P ( marked_spam ) P ( marked_spam ∣ SPAM ) P ( SPAM ) ( 2 ) = P ( marked_spam ) P ( marked_spam ∣ NOTSPAM ) P ( NOTSPAM ) ( 3 )
Subtract (3) from (2) and then use (1) in the numerator of the difference to get the desired result.
I thought that since the filter was very accurate, the email would have been a spam. Now I understand though that the filter is only 98% accurate.This means that there is still 2% to go before it's 100% accurate. While only 1% of the emails are a spam which is likely then that the email is probably not a spam. I think that the best strategy is to use logical reasoning. I would rate this problem a 2 because it was easy to understand. While solving this problem, I wasn't having trouble with solving it and it was that hard to notice my mistake.
Relevant wiki: Bayes' Theorem and Conditional Probability
From the question we know that the prior probability an email is spam, p ( spam ) = 0 . 0 1 .
Furthermore we know the accuracy on any email ( whether or not it is spam ) is 98%. Let y = 1 denote the prediction of an email of spam and y = 0 denote the prediction of an email as not spam. Then we can also say p ( y = 1 ∣ spam ) = p ( y = 0 ∣ not spam ) = 0 . 9 8 .
The degree of belief that an email is spam given the filter flags it as so is p ( spam ∣ y = 1 ) .
This can be written by Bayes' rule as p ( spam ∣ y = 1 ) = p ( y = 1 ∣ spam ) ⋅ p ( spam ) + p ( y = 1 ∣ not spam ) ⋅ p ( not spam ) p ( y = 1 ∣ spam ) ⋅ p ( spam ) .
p ( y = 1 ∣ not spam ) = 1 − p ( y = 0 ∣ not spam ) = 0 . 0 2 . Similarly p ( not spam ) = 0 . 9 9 .
Plugging in the numbers we get 0 . 9 8 ⋅ 0 . 0 1 + 0 . 0 2 ⋅ 0 . 9 9 0 . 9 8 ⋅ 0 . 0 1 ≈ 0 . 3 3 2 ≈ 3 3 . 2 % .
Given this is less than 50%, Rakesh should not believe the results with high confidence.
Haha - I read it wrong - thought it said only 1% wasn't spam - guess he's not looking for houses on Zillow!
We cannot assume that the spam filter performs as accurately on spam emails as it does on non-spam ones.
Log in to reply
This is a reasonable point. I figured that considering how it was worded this was the best interpretation despite it being a bit ambiguous.
The author actually said the spam filter is 98% accurate at identifying either type of email, so I don't get your objection.
“香烟有害健康我已经告诉你了,但你自己选择要抽,那是你自己的事了”——你要独立思考,自己选择。
Most accurate answer so far. To the top you go.
There are similar issues with the usage of the lie detector. Even if it has a very low error rate, if the "person lying" rate is lower still, than the number of false positives will be greater than the number of true positives.
Upvote for explicitly using Bayes' theorem, but as a presentation thing, wouldn't it be clearer to describe the event of positive detection with e.g. ' p o s i t i v e ' or the like, rather than introduce this variable y whose value we don't care about?
Relevant wiki: Bayes' Theorem and Conditional Probability
Suppose there are 10,000 emails.
9,900 are normal.
100 are spam.
Out of the 9,900 normal emails, 198 would be identified as spam, 9702 as normal.
Out of the 100 spam emails, 98 would be identified as spam, 2 as normal.

Wow, nice diagram! Thanks for taking the time to do that. Coupled with Luis Salazar's equations below, this makes the math super clear! Thank you.
Splendid solution, in particular the excellent diagram, which is of such clarity that IMO you could have presented wit without accompanying text.
I’m so confused. You wrote “0.98%<0.0198%”. I’m gonna round here. 1%<0.02%?????? That doesn’t make sense.
Log in to reply
sorry I mixed it up. It should've been 0.98<1.98. thanks for pointing it out. I'm going to change it.
(0.01 * 0.98 = 0.0098) is spam and marked as spam
(0.01 * 0.02) is spam and marked as not-spam (false negative)
(0.99 * 0.98) is not-spam and is marked as not-spam
(0.99 * 0.02 = 0.0198) is not-spam and is marked as spam (false positive)
More likely to be not-spam (0.0198 > 0.0098)
For convenience, let us denote the events - the filter marking a mail as spam by f = 0 , the filter marking a mail as not spam by f = 1 , a mail actually being a spam by s = 0 and a mail actually being a non-spam mail by s = 1
We are told that P ( s = 0 ) = 1 0 0 1 ⟹ P ( s = 0 ) = P ( s = 1 ) = 1 0 0 9 9
We are also told that the accuracy of Rakesh's spam filter is 98%.
From this, we deduce that P ( f = 0 ∣ s = 0 ) P ( s = 0 ) + P ( f = 1 ∣ s = 1 ) P ( s = 1 ) ⟹ P ( f = 0 ∣ s = 0 ) P ( s = 0 ) + ( 1 − P ( f = 0 ∣ s = 1 ) ) P ( s = 1 ) ⟹ P ( f = 0 ∣ s = 0 ) P ( s = 0 ) − P ( f = 0 ∣ s = 1 ) P ( s = 1 ) = 1 0 0 9 8 = 1 0 0 9 8 = 1 0 0 9 8 − P ( s = 1 ) = 1 0 0 − 1 equation ( 1 )
Notice that assuming P ( f = 0 ∣ s = 0 ) = P ( f = 1 ∣ s = 1 ) is not warranted.
Now, we are to compare the following conditional probabilities (conditioned on the spam filter saying the mails a spam) P ( s = 0 ∣ f = 0 ) and P ( s = 1 ∣ f = 0 )
Using the Bayes Theorem, we see that P 1 = P ( s = 0 ∣ f = 0 ) and similarly P 2 = P ( s = 1 ∣ f = 0 ) = P ( f = 0 ) P ( f = 0 ∣ s = 0 ) P ( s = 0 ) = P ( f = 0 ) P ( f = 0 ∣ s = 1 ) P ( s = 1 )
Consider the difference D = P 1 − P 2 .
D = P ( f = 0 ) P ( f = 0 ∣ s = 0 ) P ( s = 0 ) − P ( f = 0 ) P ( f = 0 ∣ s = 1 ) P ( s = 1 ) = P ( f = 0 ) − 1 / 1 0 0 from equation ( 1 ) < 0
We therefore conclude - given that the spam filter says the mail is a spam, the probability that the mail is actually a spam is less than the probability that its actually a normal mail.
Yes, this should be the correct answer.
Thanks !!! Thanks !!! Thanks !!! Thanks !!! Thanks !!! Thanks !!! Thanks !!!
Here is another solution by drawing a tree diagram. If the mail is spam it goes into Junk folder. If the mail is not spam it goes into Rakesh's Inbox.
We know the following:
- From all the messages Rakesh receives, 1% is spam and 99% is normal mail.
- We also know that his spam filter is 98% accurate both ways. This means that the probability that a normal mail will be sent to Inbox is 98%, while the probability that a normal mail will be sent to Junk folder is 2%. Similarly, the probability that a spam mail will be sent to Junk folder is 98% and the probability that a spam mail will be sent to Inbox is 2%.
We can know draw the diagram:
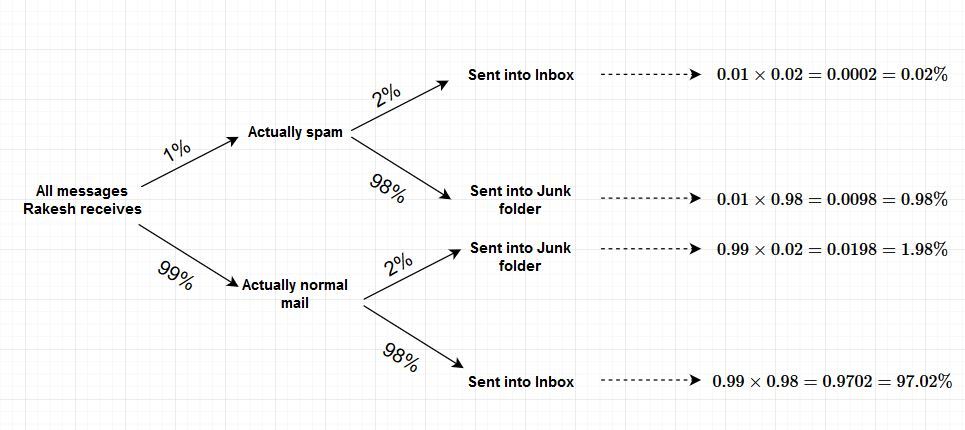
As you can see from the diagram, the probability that a message is both spam and it ends up in Junk folder is 0.98% and the probability that a message is both normal and it ends up in Junk folder is 1.98%.
Therefore, if Rakesh gets an e-mail in his junk folder it is more probable that this message is actually normal mail mistakenly identified as spam than the message actually being spam.
Why is that so? Well, in this problem the spam filter is equally effective (or innefective) in identifying both spam and normal mail. However, Rakesh receives very little spam mail (only 1%). Just because 99% of his messages are normal, it is more likely that a normal mail will be flagged as spam than actually receiving a spam message.
Interestingly enough, if exactly 2% of all messages Rakesh receives are spam, than a message which ends up in junk folder is equally probable to be either spam or normal mail (1.96%). Try and calculate this for yourselves.
It's the paradox of the false negative. If the percentage of accuracy of the test is less than the probability that a perfect test would return negative, then the test returns more false positives than necessary. Lets say that there is a disease, called Math Deficiency Disease, that affects 6.9 percent of people. Now, scientists have made a way to test for MDD, which is correct 93 percent of the time. What is the percentage of people who had tests return positive who do not have MDD? A 1% B 0.1% C 51.8...% D 50.3...%
What drew me to doing this question was that in my math course, my professor did a question with us just like this but was looking at mammography results instead of spam emails.
We know that the spam detection is 98% accurate and that 1% of all the emails are actually spam
Let's assume there are 10 000 emails we assume that a true positive is correctly identifying spam email as spam and true negative is correctly identifying a true email as a true email
1% of emails are spam, therefore in his inbox there are: spam emails = 10 000x0.01 = 100 true emails = 10 000x0.99 = 9900
let's work with the spam first with 98% detection ability, of those 100 spam emails: 100x0.98= 98 will be correctly identified as spam (true positives) 100x0.02= 2 will be falsely identified as true emails (false negatives)
now let's work with the true emails with 98% detection ability, of those 9900 true emails: 9900x0.98= 9702 emails will be correctly identified as true emails (true negative) 9900x0.02= 198 emails will be falsely identified as spam emails (false positives)
And back to the original question, Which is more likely to be true if he receives an email that his filter predicts is spam?
well if he is told his email is spam and assuming there are 10 000 emails:
296 emails in total are identified as spam where: 98 of the emails identified as spam are actually spam 198 of the emails identified as spam are actually true emails
Therefore, the email is most likely NOT to be spam and is most likely to be a true email.
thanks for coming to my TedTalk.
P.S: shout out to my math prof for teaching me how to solve questions like this
I didn't even use math... I just thought about my friends and I. We send spam even in our IMPORTANT messages. (I broke the system, guys)
I had a spam filter with 99.5% accuracy, it marked everything as spam. Only 1/200 mails were non-spam; all non-spam were marked as spam. Yay for neural networks.
Two edgecases, out of 100 mail:
Case 1: 0 from the spam and 2 from the non-spam are incorrect.
Case 2: 1 from the spam and 1 from the non-spam are incorrect.
(Out of 100 mail, the possibility of 2 spam isn't there. SImplify.)
Case 1: All mail marked spam is non-spam (alternative 2)
Case 2: Half the mail marked spam is non-spam (not an alternative)
The answer is probably between case 1 and case 2 (alternative 2).
Intuitively, the overwhelming probability is that the email will not be spam, regardless of the result of the filter test. This can be shown with truth tables, as others have demonstrated.
I would not call them truth tables. Truth tables do not usually contain probabilities.
Spam Filters are effective sometimes. The question is how accurate it needs to be in order to be effective.
For every 100 emails, 98 are identified accurately, 2 are identified inaccurately.
For every 100 emails, 99 are normal, 1 is spam.
We can represent this with a chart (essentially one with 1 0 0 × 1 0 0 = 1 0 0 0 0 entries):
The only emails we care about for this question are the emails identified as spam.
Out of 1 0 0 0 0 emails, normal mail is identified as spam 9 9 × 2 = 1 9 8 times.
Out of 1 0 0 0 0 emails, spam mail is identified as spam 9 8 × 1 = 9 8 times.
Since 1 9 8 > 9 8 , it's more likely a spam-identified email is actually not spam!