Monkey's Typing Challenge

A monkey is typing a string of random letters, with all letters equally (and independently) likely to be typed.
Which word is more likely to appear first in the string, heart or earth?
This section requires Javascript.
You are seeing this because something didn't load right. We suggest you, (a) try
refreshing the page, (b) enabling javascript if it is disabled on your browser and,
finally, (c)
loading the
non-javascript version of this page
. We're sorry about the hassle.
6 solutions
Small flaw: you don't acknowledge the possibility that EART occurs at position zero, in which case EARTH might appear but HEART has no chance. This offsets your conclusion, but since this circumstance only happens with probability 1/26^4, your answer is still good.
Log in to reply
This small flaw (omission) becomes of paramount importance as the word length shortens down to 2 letters (HE vs. EH in Gregory Lewis' example below).
Amazing explanation !
I don't think that's right... By the same logic, wouldn't we conclue that THEAR would probably come sooner than HEART (using the HEAR string). And then couldn't we say that RTHEA will probably come sooner than THEAR... and then we could say ARTHE will probably come sooner than RTHEA... Finally, we would claim that EARTH will probably come sooner than ARTHE...
We just made a loop! By transitivity, we just showed that EARTH will come before HEART ! I think the problem with studying the string EART is that if these are exactly the first four letters that the monkey types, there is zero probability that an H comes before, while there is 1/26 chance that the word EARTH will be spelled.
I believe the probabilities are equal.
Log in to reply
Nice reasoning
I am adding a comment to my own because I realize now that what I wrote above wasn’t correct. I actually had a great exchange of ideas with a couple of people at brilliant.org who helped me understand how my logic wasn’t right. It was very enriching.
Even though the idea I present of forming a “loop” seemed attractive, I understand now that this is not a transitive process. It is possible for each step in the loop to be true without forming a contradiction. To keep it short, I think the best intuitive way to be convinced of the result is to play around with a much smaller alphabet and a smaller string of letters.
If the alphabet has only two letters, A and B, then we can check which one of ABB or BBA has a higher chance of showing up first. It is not 50%-50%. There are eight ways the monkey’s string may begin: AAA… AAB… ABA… ABB… BAA… BAB… BBA… BBB…
We of course notice that ABB and BBA both show up once. Unsurprisingly, there is a tie after three letters in that respect. However, if we look at the other six possibilities, they lean clearly in favor of ABB showing up first in the near future. AAA is only two letters away from completing ABB whereas it’s three letters away from completing BBA. AAB is only one letter away from completing ABB whereas it’s two letters away from completing BBA. ABA is two letters vs three letters away from the words. BAA is two letters vs three letters away. BAB is one letter vs two letters away. In fact, only BBB is now closer to completing the second word, since it’s only missing one letter to complete BBA (and three letters away from ABB). By extending the eight strings to see what happens further, we would see that it just confirms or even increases this unbalanced trend.
I know this is not a proof at all, but I just wanted to amend my own comment.
Sorry for my late response. I saw this problem on Facebook and saved it for later as I was busy. That later is now (as I sometimes don't use Facebook for weeks or even months).
A very simple example of non-transitive probabilities: we run around the circle on and on and stop at a random point. The circle has 3 equally spaced points marked A, B and C.
Now that we stopped, we start again and check whether we are more likely to encounter A or B first. There are 3 equally probable possibilities: we first encounter A, B or C. If we first encounter B, then B is before A. If we encounter A first, then A is before B. If we first encounter C, then we follow CAB, so A is before B.
Summary: the probability that A is before B is 2/3 and B before A only 1/3. So we're more likely to encounter A before B.
It's also easy to work out that it's more likely to encounter B before C. Also C before A. So a loop. And the difference is not insignificant: 2/3 vs 1/3.
The way probability transitivity works is: if X is before Y with probability p and Y before Z with probability q, then X is before Z with probability at least p+q-1. Even with p=q=2/3 that probability may (and in my example does) equal only 1/3. In the HEART/EARTH/ARTHE example probability is only marginally over 1/2, so transitivity promises almost nothing; with more values it promises nothing.
monkey will type zlatan!
Interesting part is, Probability is not "transitive".. in the sense that Heart will "beat " Earth which will beat Arthe, which will beat rthea which will beat thear which will beat heart. (IOW if two people have to choose one word (from these above 5) the second person will "win".
This logic has a fatal flaw: substitute EART with E and it proves that HE is more likely to come before EH! Swap the H and EART and change the numbers a bit and you've proven that EARTH is more likely to come before HEART!
The problems are twofold: the string could begin with EART, or EARTEART could appear in the string. Both of those reduce the probability that EART is preceded by H. What makes this different than HE vs EH is that the probability of those happening is much lower.
Intuition
On first read this might seem like a trick question.
Suppose we go to position i in any string S prepared with the method described in the problem. There is, of course, an equal probability for the string S i : ( i + 4 ) to be EARTH or HEART , equal to 1 / 2 6 5 .
But what is the probability for it to be EARTH or HEART given that neither EARTH nor HEART have appeared yet?
Suppose we want to know the probability of the string starting at position i being EARTH AND that it is the first time that either EARTH or HEART appear in the string. What we need to worry about is the following: if S i : ( i + 4 ) is to be the first appearance of EARTH , then S ( i − 1 ) cannot be H or else we'd have S 0 S 1 ⋯ S i − 2 HEARTH and HEART would slide into the win just as EARTH was to appear.
Similarly, if it is to be HEART AND the first time that either HEART or EARTH appear in the string, then the substring S ( i − 4 ) : ( i − 1 ) cannot be EART .
From here, it's already clear that we're less likely to have S ( i − 4 ) : ( i − 1 ) = EART than we are to have S ( i − 1 ) = H , so HEART is more likely to appear first. But to get quantitative, we have to do a calculation.
Calculation
We can write these probabilities as
P ( EARTH = S i : ( i + 4 ) A N D H = S ( i − 1 ) ∣ ∣ ∣ ∣ { EARTH , HEART } ∈ / S 0 : ( i − 1 ) )
and the corresponding one for HEART as
P ( HEART = S i : ( i + 4 ) A N D EART = S ( i − 4 ) : ( i − 1 ) ∣ ∣ ∣ ∣ { EARTH , HEART } ∈ / S 0 : ( i − 1 ) )
Note that both of these probabilities are conditioned upon neither EARTH nor HEART appearing in S 0 : ( i − 1 ) , so we don't have to worry about the likelihood of those events occurring. For simplicity, we'll write the first expression above as P i ( EARTH ) from here on, and likewise for the HEART probability.
For the first expression above we need S ( i − 1 ) = H , S i : ( i + 3 ) = EART , and S ( i + 4 ) = H . Thus,
P i ( EARTH ) = P ( S ( i − 1 ) = H ) × P ( EART ) × P ( H ) and likewise P i ( HEART ) = P ( S ( i − 4 ) : ( i − 1 ) = EART ) × P ( H ) × P ( EART )
Thus, the probability that HEART appears in S before EARTH is given by
P ( HEART before EARTH ) = P i ( HEART ) + P i ( EARTH ) P i ( HEART ) = P ( S ( i − 4 ) : ( i − 1 ) = EART ) × P ( H ) × P ( EART ) + P ( S ( i − 1 ) = H ) × P ( EART ) × P ( H ) P ( S ( i − 4 ) : ( i − 1 ) = EART ) × P ( H ) × P ( EART ) = P ( S ( i − 1 ) = H ) + P ( S ( i − 4 ) : ( i − 1 ) = EART ) P ( S ( i − 4 ) : ( i − 1 ) = EART )
After the cancellations, the probabilities we're left with are simple. If the size of our alphabet is A , then P ( S ( i − 1 ) = H ) P ( S ( i − 4 ) : ( i − 1 ) = EART ) = 1 − A − 1 = 1 − A − 4 and P ( HEART before EARTH ) = 2 − A − 1 − A − 4 1 − A − 4 .
Estimate
For the 26 letter alphabet, A − 4 is very small compared to A − 1 , so we can neglect A − 4 and expand in A − 1 as follows P ( HEART before EARTH ) ≈ 2 1 ( 1 + 2 A 1 ) = 2 1 + 4 A 1 ≈ 0 . 5 0 9 6 …
The exact probability is approximately 0 . 5 0 9 8 0 3 3 7 4 7 0 3 6 6 7 5 4 9 8 5 .
Generalization
We can generalize this to the case of alphabets of size A ≥ N where N is the length of the two words. In our specific case A was 26 and N was 5. For general A and N , we have
P ( N , A ) = 2 − A − 1 − A − ( N − 1 ) 1 − A − ( N − 1 ) .
Simulation
Given how surprising the result is, it is reassuring to verify it by explicitly performing the suggested typing exercise.
Below are the results when we run the experiment on small alphabets of size A equal to the length of the two words. E.g. for A = 4 , we check whether DABC or ABCD appears first when we enumerate random strings from the alphabet { A , B , C , D } .
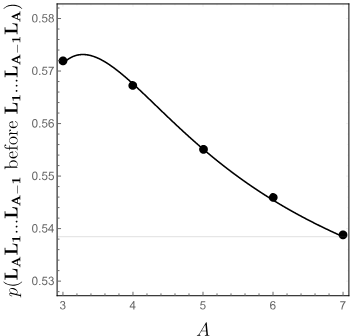 Simulation results for
N
=
2
0
0
0
0
0
random typing experiments.
Simulation results for
N
=
2
0
0
0
0
0
random typing experiments.
There seems to be close agreement between our prediction and the simulation.
For reference, the code is below. You can also add letters not in either of the competing words by uncommenting/adding to the list
extra
.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
@Josh Silverman , @Eli Ross - Wow!! Awesome question and awesome solution!
So I assume this amazing solution is the reason for this problem being in the 'advanced' problems of the week, not the actually problem itself then :)
You should be using a bunch of typewriters and monkeys to prove the result though :)
Log in to reply
As long as they are interested, I can't see a problem with that.
In a string of indefinite length, consider all instances of the sub-string "EART" Let Z be any letter that is not H. Then we can have sub-strings ZEARTZ, HEARTZ, HEARTH, ZEARTH that can occur.
If HEARTZ is equally likely as ZEARTH to first occur, then because of some chance that HEARTH can be the first to occur, then HEART is more likely to be the first to occur.
Now that Josh Silverman has posted his full solution with the computed probability, let's look at the probability of just one H appearing either at front or back of EART, and the probability of appearing both
A
=
2
6
1
2
6
2
5
B
=
2
6
1
2
6
1
Hence, the probability of HEART appearing first should be
2 A + B A + B = 0 . 5 0 9 8 0 4 . . .
which almost agrees with Josh's figure. Right now I"m not ready to say that my figure here is correct.
Edit: Josh's figure is the accurate one. The solution provide here is still only an approximation, as it does not distinguish between the two cases in that small chance of EART appears in the first few letters of the sequence. My solution neglects the small chance that the sequence begins with EART. Both figures agree to six decimal places, and then diverges.
In my solution I used linear algebra to find the exact probability. Your approximation is close within 0.02%! (Compared to the fact that HEART is about 2% more likely than EARTH.)
Log in to reply
Wondering if we're dead on @Arjen Vreugdenhil , the formula I arrive at gives 0.50980337470 for the probability of HEART before EARTH.
Log in to reply
Yes, I believe your boxed formula (and its generalization for P ( A , N ) ) is identical with my solution. The denominator in your solution is likely the determinant of the matrix I used, up to some trivial factor.
What is the likelihood that the first instance would in fact be HEART, with the next, (or 6th,) letter being an H? I just thought it would be neat if that were to happen because the addition of a single letter could make both words in the five letter format, be found in order. Although the probability of such an occurence is likely very low. Nor would this supposition change the original outcome.
We can think of this process as an automaton, with the following states and transitions:
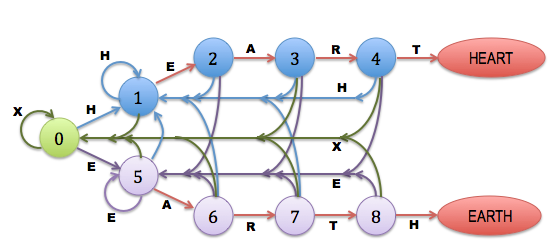 (blue line: H; purple line: E; green line: other letter (X))
(blue line: H; purple line: E; green line: other letter (X))
state start: 0 1 2 3 4 5 6 7 8 H 1 1 1 1 1 1 1 1 x E A R T H E 5 2 5 5 5 5 5 5 5 A 0 0 3 0 0 6 0 0 0 R 0 0 0 4 0 0 7 0 0 T 0 0 0 0 H E A R T 0 0 8 0 other 0 0 0 0 0 0 0 0 0
Let P ( s ) indicate the probability that a state s will eventually lead to the finals state H E A R T . The probability of x E A R T H is then 1 − P ( s ) . Treating P ( ⋅ ) as a vector, we may write the transition probabilities as follows, where α = 2 6 1 is the probability of an individual letter: P ( s ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 1 − 2 α 1 − 2 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 2 α α α α α α α α α α α α α α α α α α α α α α α ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P ( s ) + ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 0 0 α 0 0 0 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ . This can be reduced to ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ − 2 α 1 − 2 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 3 α 1 − 2 α α α − 1 α α α α α α α − 1 α − 1 α − 1 α α α α α − 1 α α α α − 1 α − 1 α − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ P ( s ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 0 0 − α 0 0 0 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ .
Lazily, I solved this numerically and found P ( s ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 . 5 0 9 8 0 3 0 . 5 0 9 8 0 4 0 . 5 0 9 8 3 1 0 . 5 1 0 5 2 9 0 . 5 2 8 6 5 7 0 . 5 0 9 8 0 2 0 . 5 0 9 7 7 4 0 . 5 0 9 0 4 9 0 . 4 9 0 1 9 6 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ . Specifically, P ( S ) = 0 . 5 0 9 8 0 3 > 2 1 , so that the final state H E A R T is more likely than x E A R T H .
Note that this is true at any point during the process, except in state 8 : at that point, the outcome x E A R T H is slightly more probable.
It seems like S is a container for any letters not in H E A R T , but what is x supposed to represent?
Log in to reply
You should realize that my notation S , H E , x E A etc. does not refer to (sub)strings but to states of the automaton. As the string is feed into the automaton, each character corresponds to a transition from one state to another. Perhaps I should have numbers the states 0 , 1 , 2 , 3 , 4 , 5 , 1 ⋆ , 2 ⋆ , 3 ⋆ , 4 ⋆ , 5 ⋆ or something like that, to avoid confusion.
S = initial state. We return to this state when we cannot possibly be in EARTH or HEART at the moment;
xEA = state obtained after a non-H, E, and A in that order.
Log in to reply
Ah I see, that's why S is its own state, it's just the restart state. Yea I think it would help to show a sample string of states for the automaton, or simply the cycles of the state space.
Log in to reply
@Josh Silverman – I will post a diagram and use numbers for the states instead of letters. That should clarify matters.
If we replace the vector in the last equation by ⋯ = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ − 1 − 1 − 1 − 1 − 1 − 1 − 1 − 1 − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ , and solve, we find the expected number of moves to reach one of the two words from any given state. E ( s ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 6 0 5 7 1 7 8 6 0 5 7 1 6 6 6 0 5 6 8 3 4 6 0 4 8 2 1 8 5 8 2 4 2 1 0 6 0 5 7 1 6 5 6 0 5 6 8 3 4 6 0 4 8 2 1 8 5 8 2 4 2 1 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ . Thus, the monkeys will on average need slightly more than 6 million keystrokes to write either HEART or EARTH.
Naively, one might estimate this number of keystrokes as E ≈ 2 2 6 5 = 5 9 4 0 6 8 8 , which is pretty close to the true value. The actual number of keystrokes is slightly bigger because the probabilities of typing EARTH and HEART are not entirely independent.
No need for a bunch of math here. On average the letters EART will show up after some expected number of letters are chosen. The probability that an H will be in front of the E is the same as the probability that an H will be behind the T, but when both the letter before the E and after the T are H, HEART wins. This means there are more ways for for HEART to win than for EARTH to win.
Exactly - and quite how so many people got this one wrong is a mystery to me as it is not remotely difficult to arrive at the conclusion you have produced above. This problem is two categories out of place as a p;roblem of the week.
If we ignore the possibility of EARTH appearing as the first characters (1 in 11,881,375) this is analogous to two people taking turns flipping a coin and the winner being the first to land heads. The person who goes first has a clear advantage: 1/2 + 1/8 + 1/32... versus 1/4 + 1/16 + 1/64...
In this case the aim is to type an H first, and the Heart team goes first, so has the advantage.
The occurrence of EART can be ignored, it is simply the trigger for each turn, but the probabilities would be the same without it —the game would just be a lot quicker.
In a random string of letters, the words HEART and EARTH have equal probabilities, but HEART is more likely to appear nearer to the beginning of the string.
The two words in question share the substring EART . Imagine searching through a random string and finding the first instance of EART . In the context of this question, we care about three scenarios:
The probability of scenario 1. is 2 6 1 ≈ 0 . 0 3 8 5 since the letters are selected independently. Notice that it doesn't matter if EART is followed by H here because HEART + H would still count as HEART appearing first.
Similarly in scenario 2., the probability that EART is followed by H is 2 6 1 since the letters are selected independently. But the letter preceding EART cannot be H , or it would count as HEART appearing first. The probability that the preceding letter is not H is 2 6 2 5 , so the joint probability is 2 6 1 × 2 6 2 5 ≈ 0 . 0 3 7 0 .
We can see that each instance of substring EART has a 0 . 3 8 5 % chance of forming the word HEART , but only a 0 . 3 7 0 % chance of forming the word EARTH and not the word HEART . Thus, HEART is slightly favored to appear first in a random string.