Sprinkler Zone
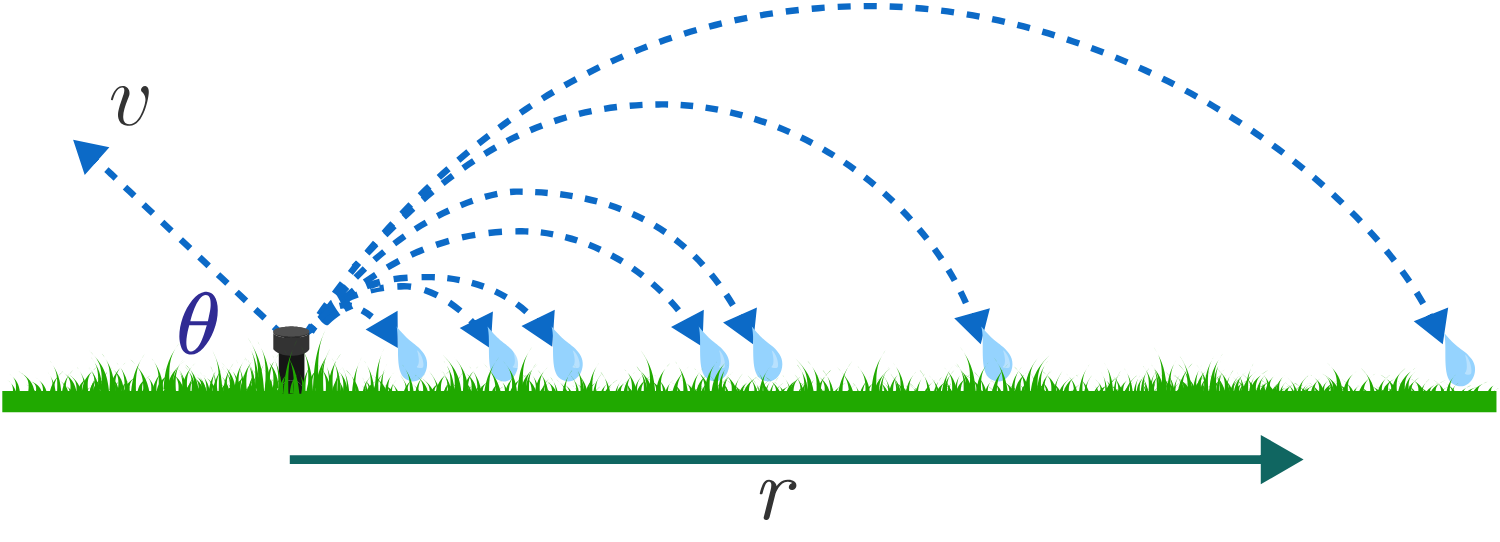
A stationary lawn sprinkler waters a circular region of grass by launching water droplets at an angle of θ = 3 0 ∘ above the horizontal in all directions.
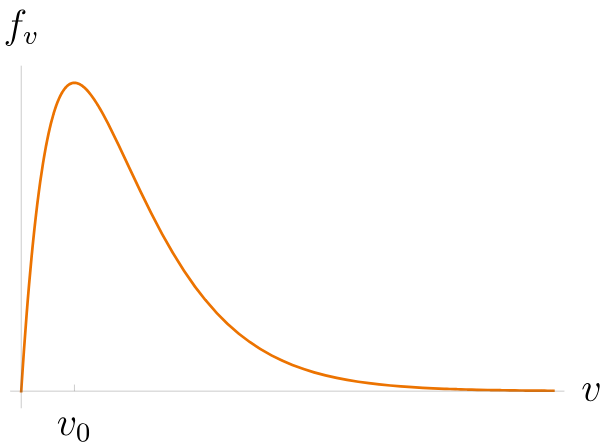
The water droplets leave the sprinkler with a range of speeds 0 < v < ∞ according to the velocity distribution f v ( v ) = v 0 2 v e − v / v 0 . The probability that a droplet is launched with a speed between v and v + d v is f v ( v ) d v , so the most likely speed is v 0 , the maximum of f v .
If the droplets follow parabolic trajectories with acceleration g toward the ground, find the probability distribution describing the distance r where a droplet lands on the grass.
What is the most likely distance (in meters) from the sprinkler that a droplet lands?
Assumptions:
- Air drag is negligible.
- The height from which the droplets are launched is negligible.
- The most likely speed of a droplet is v 0 = 1 m / s , and g = 1 0 m / s 2 .
The answer is 0.0.
This section requires Javascript.
You are seeing this because something didn't load right. We suggest you, (a) try
refreshing the page, (b) enabling javascript if it is disabled on your browser and,
finally, (c)
loading the
non-javascript version of this page
. We're sorry about the hassle.
4 solutions
So it turns out that the mode of the square is not the square of the mode...?
Log in to reply
Indeed. No reason why it should be with a continuous distribution.
This is a word-game problem. Not my liking ;-)
Mark, can you please see my comments to Josh Silverman's post here, and tell me of any thoughts you may have on this?
Log in to reply
The problem is that you are saying that we should determine the value of r conditional on knowing about the value of v . Obviously, if we know v , there is little to determine about r . However, if we are only concerned with the final landing spot, we have not previously determined v , and hence all possible values of v could have occurred, which changes the probability distribution of r to the one given here.
As an analogy, consider drawing three cards, without replacement, from a pack. We can ask what the the probability is that the third card is an Ace. Answer: 1 3 1 . However, if we know the values of the first two cards, the probability that the third card is an Ace is different. Asking that we should determine r by knowing the prior value of v is like asking for the value of the first card when wanting to know the value of the third.
Look at the problem yet another way. Suppose that we had a series of hygrometers installed in the ground, measuring the amount of water that lands at particular radii from the sprinkler. While the most likely value of v is v 0 = 1 , small variations of v will result in varying variations of r , depending on the value of v , and this variable variation means that the part of the lawn nearest to the sprinkler will get the greatest soaking.
Log in to reply
Here are two ways we can look at this problem:
1) We ask which part of the ground gets the most soaking
2) We ask, for a particular water droplet, what's the most likely distance it will travel
Both are valid questions to ask. What I want to know, why do we say that the "the most likely distance that a droplet lands" is at r = 0 ? There is a subtle difference between scenarios 1) and 2). Why is it supposed that because the ground is most wet near r = 0 , that's where a particular droplet leaving the nozzle is most likely to land? Let's say 100 droplets leave the nozzle and land at various distances, two of the landing at 0, and the rest landing in a very tight cluster near 100. Technically, since the most frequent specific distance is 0, since there's two of them, while all other distances near 100 are unique, is it really meaningful to say that a droplet leaving the nozzle is "most likely to land straight down"? I think the more accurate wording should be, "where are we most likely to find a dropet of water on the ground?"
I gave the illustration of that slot machine. Would you be willing to just keep on playing it, or are you going to say, "I'm most likely going to get nothing, so I won't play"?
Yes, I agree that interpretation 2) makes the problem trivial, but it isn't trivial to make the claim that because the ground is most soaked near r = 0 , that's where a droplet leaving the nozzle is most likely to land. Imagine if medical diagnosis and treatment was based on this kind of thinking.
Log in to reply
@Michael Mendrin – There is a good analogy here with quantum mechanics. If we conduct a Young's slit experiment with light so attenuated that only only photon is passing through the slits at any one moment, we still see a diffraction pattern, but if we measure which slit the photon passes through, thereby collapsing the wave-packet, the pattern disappears. Your asking that we investigate the behaviour of a single droplet is, in essence, requiring that we measure v before r , and this effectively collapses the wave packet. If all we saw of that individual droplet is where it landed (and not how it got there), we would not have collapsed the wave packet, and therefore would obtain 0 as the modal distance from the sprinkler. Once we start asking "what is the most likely flight-path for a droplet?" (which is what I think you really mean in (2)) we are asking a different question.
Medical diagnosis is full of problems of this nature. Imagine a test for an illness which correctly diagnoses a patient who is sick 99% of the time, and only misdiagnoses a well patient 1% of the time. If 1% of the population has this illness, then a patient who tests positive for the illness only has a 50% chance of actually being ill. That's why doctors perform multiple (and more than one) tests!
Log in to reply
@Mark Hennings – Let's say clinical trials are conducted for a new drug. The results of the trial are very similiar to the slot machine analogy I gave, where out of 7000 patients adminstered with the drug,
1000 of them had 0 improvement
3000 of them had 1 improvement
2000 of them had 4 improvement
1000 of them had 9 improvement
When the density distribution is plotted out with "improvement" as the variable, the peak will be at 0 improvement. Do we then say that "a patient, when given this drug, is most likely not to show an improvement?" But in fact, when a particuliar patient is given the drug, the most likely outcome, between 0, 1, 4, 9, is 1. Even 4 is more likely than 0. There is a disconnect between wondering what is likely to happen to a typical patient given this drug, and noticing how the reported outcomes are clustered. The two are not necessarily synonymous.
Do doctors really pay attention to such fine distinctions? The answer, unfortunately, is too frequently no. There have already been papers written about this problem of doctors not fully understanding these kinds of statistical interpretations. Yes, good doctors will call for more testing, in case of potential false positives.
Log in to reply
@Michael Mendrin – The problem you are concerned about does not occur with discrete distributions such as this drug model - if you change the positions of the bars in a bar chart, their heights are unchanged. It strikes me as dodgy to try to make a continuous distribution of this data. If, in 7000 tests, nobody came up with 2,3,5,6,7,8 improvements, we would tend to doubt the possibility of such outcomes, and certainly doubt attempting to smooth this discrete distribution into some sort of continuous distribution. The same comment applies, with even greater strength, to your slot machine model. Its outcome has a discrete distribution, and it is incorrect to try to model it by a continuous distribution - if you do, you can expect to get weird results.
Whatever doctors may do, medical researchers work closely with statisticians, who are well aware of these issues.
Log in to reply
@Mark Hennings – I'm using just a few outcomes in an effort to illustrate what is going on when it's done in continuous form. If given enough data and outcomes, it can be made as close to a true continuous plot. In fact, didn't Josh just do that? Which is to treat it in discrete form, but using a lot of data points? 20,000 of them instead of just 7?
I'm not here to make commentary on medical practice, I'd like to better understand what's happening when a density plot is compiled. If the way I'm doing it is "dodgy" which "can produce wierd results", what's the correct method?
By the way, I would LOVE it if somehow investigation into these kinds of "statistical interpretations" would help us understand quantum wierdness, but alas, that's never gonna happen. Quantum wierdness IS truly wierd and cannot be explained in terms of how we interpret statistics.
Log in to reply
@Michael Mendrin – Once you are looking at thousands of datapoints, a continuous approximation starts to become appropriate, and you start to get the effect that my solution showed, and Josh's calculations modelled. A larger velocity produces a larger range, but also a small change in a larger velocity results in a larger change in range ( r ∝ v 2 , and so δ r ∝ v δ v ). Thus peaks in v get "thinned out", and can (in an extreme case such as this) be totally wiped out.
Just because the modal droplet distance is 0 does not mean that the lawn does not get watered! As is often true, the mode is frequently a statistic of dubious worth, and may not even exist. A much happier picture of lawn health can be obtained by considering the mean or median droplet distance!
Some aspects of QM are truly weird, but many of the apparent weirdnesses can be cleared up through sensible statistical thinking.
Log in to reply
@Mark Hennings – "...many of the apparent weirdness can be cleared up through sensible statisical thinking". Now THAT is a subject really worth sinking one's teeth in. We know that statistics can be modelled via Monte Carlo methods, like how it's successfully done with classical thermodynamics. Is it possible to "simulate" any kind of quantum weirdness with such Monte Carlo methods, using an ordinary computer, not a quantum one? You mentioned the quantum behavior of a single photon passing through a double slit. How could that be explained "through sensible statistical thinking", without the circular reasoning of first assuming and then using quantum probability rules in which to perform computations? Textbooks in quantum physics are replete with computer simulations, but they all use quantum probability rules as a given.
Log in to reply
@Michael Mendrin – To accept the implications of a model, and argue correctly within it, is not circular thinking. QM is only a model, currently justified (in the absence of a full rigorous development, despite 100 years' worth of trying) by its high degree of experimental accuracy. If, as and when a better model comes along, fine. Until then, you have to play by its rules.
Log in to reply
@Mark Hennings – Okay, if you include quantum probabilities as all part of "sensible statistical thinking", we're on the same page. But I do seem to recall that Richard Feynman said that he didn't think it would be possible to do a computer simulation of quantum behavior without resorting to using a quantum computer. In other words, there's "classical statistics", and there's "quantum statistics", and the latter cannot be explained by the former. No card trick peformed by any magician can ever replilcate quantum behavior, without maybe using special cards that somehow use the Bloch sphere, or with just downright cheating. Ahh.. but this will get us too deep here.... But anyway, thanks for your comments about this particular sprinkler problem.
I banged my head for awhile trying to figure out what this question was asking for, but here's what I eventually came to:
1)
Suppose the landing distance is
R
, and we divide the range of possible
R
values into little bins of equal width
d
R
2)
Each little bin of width
d
R
has an associated
d
v
, which I will show shortly
3)
The probability of being in that particular bin of width
d
R
is equal to
f
v
d
v
4)
Find the
R
value which maximizes the quantity from (3)
The relationship between v and R is:
R = g 2 v 2 s i n θ c o s θ v 2 = 2 s i n θ c o s θ g R
We're interested in the relationships between the infinitesimals, so differentiate both sides with respect to R :
2 v d R d v = 2 s i n θ c o s θ g = α d R d v ∝ v 1
If we think of all the R bins as having equal width, this comes to:
d v ∝ v 1 f v d v ∝ v 1 v e − v / v 0 f v d v ∝ e − v / v 0
The probability of being within a bin of width d R is, somewhat counter-intuitively, maximized when the speed is zero, and the corresponding landing distance is zero. Or if you're uncomfortable with the 0/0 division that would imply when looking at some of the earlier math, you could pick some arbitrarily small value ϵ
The problem is first asking for the distribution of water as a function of distance r , and then finding r where it's the maximum. In this case, it occurs when v = 0 for f v d v ∝ e − v / v 0 as you have pointed out.
This problem highlights the subtleties of working with related probabilistic quantities. On first look things seem very counterintuitive: how can it possibly be that the most probable range for the projectile isn't the same thing as the range the projectile has when it's launched at its most probable speed? Given how much there is to grapple with, I wanted to fill in some of the context for the underlying manipulation of probability densities.
To get started, realize that the probability of any particular point in continuous distribution is zero. If we draw random reals from the range ( 3 , 4 ) , there are an infinite number of possible numbers that can be drawn from the range, and each number is uniformly probable, so the probability of drawing any given real number is zero. Yet, we can confidently state that there is a 2 0 % chance of drawing a number that's between 3 . 3 and 3 . 5 .
What this echoes is that we need to think about the probability of drawing a number from the neighborhood around a point, not the probability of a single point. Let's define P ( v a , v b ) as the probability of drawing a number in the neighborhood between v a and v b . In terms of the probability density function f v ( v ) , P ( v − Δ v , v + Δ v ) is the integral P ( v − Δ v , v + Δ v ) = v − Δ v ∫ v + Δ v f v ( v ) d v .
Like @Steven Chase and @Mark Hennings point out, the range r for a projectile is related to its launch speed v and launch angle θ by r ( v ) = 2 v 2 g − 1 cos θ sin θ , which we can write more simply as r = k v 2 . This allows us to change between values of v and values of r . Because each outcome of v corresponds to a physical outcome of r , it must be true that the probability of observing a velocity in between v a to v b is equal to the probability of observing a range between r ( v a ) and r ( b v ) .
In other words:
P v ( v a , v b ) v a ∫ v b f v ( v ′ ) d v ′ = P r ( r ( v a ) , r ( v b ) ) = r ( v a ) ∫ r ( v b ) f r ( r ′ ) d r ′
We can use this equality to find the probability density of r , f r ( r ) , in terms of the probability density of v , f v ( v ) . For simplicity, we can set v a = 0 (which implies r ( v a ) = 0 , and let v b = v vary so that we can just think about P ( 0 , v ) = P v ( v ) , the probability of observing a velocity between 0 and v .
From above, we have
P v ( v ) 0 ∫ v f v ( v ′ ) d v ′ = P r ( r ( v ) ) = 0 ∫ r ( v ) f r ( r ′ ) d r ′ .
How can we generate a relationship between the integrands? We can take the derivative of both sides with respect to one of the integration variables and use the chain rule to connect them.
Taking the derivative of both sides with respect to v , we have f r ( r ) = d r d 0 ∫ v f v ( v ′ ) d v ′ = d r d v ⋅ d v d ⎣ ⎡ 0 ∫ v f v ( v ′ ) d v ′ ⎦ ⎤ = d r d v f v ( v )
Using the relationship between r and v , we can see that d r d v = k 1 d r d r = 2 1 k r 1 .
which gives us f r ( r ) = 2 1 k r 1 f v ( v ) = 2 1 k r 1 v 0 2 v e − v / v 0 . Upon replacing v with v ( r ) , we find
f r ( r ) = 2 1 k r 1 k r v 0 2 1 e − r / k / v 0 = 2 k v 0 2 1 e − r / k v 0 2
Obviously, f r is maximized when r is 0 , and this means that the probability of ranges is highest in the neighborhood of r = 0 . We can check to see that this is true by randomly sampling v from the probability density f v ( v ) , transforming them according to r = k v 2 , and making a histogram of the corresponding values of r .
Here is a random sample of 20,000 speeds drawn from the distribution
f
v
(
v
)
,
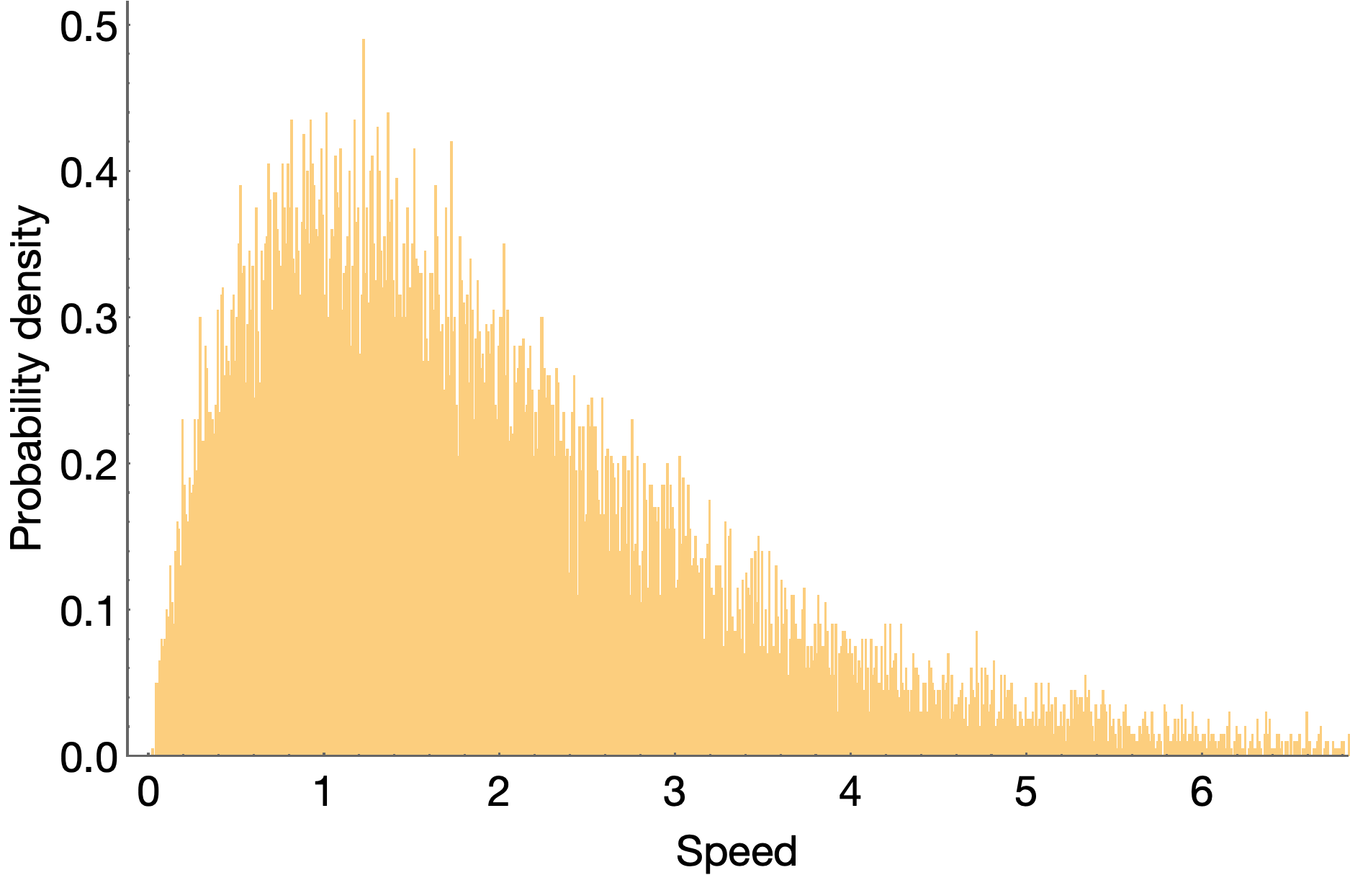
and here is the distribution of ranges, which is obtained by simply transforming each value in the histogram above according to
r
=
(
2
g
−
1
sin
θ
cos
θ
)
v
2
:
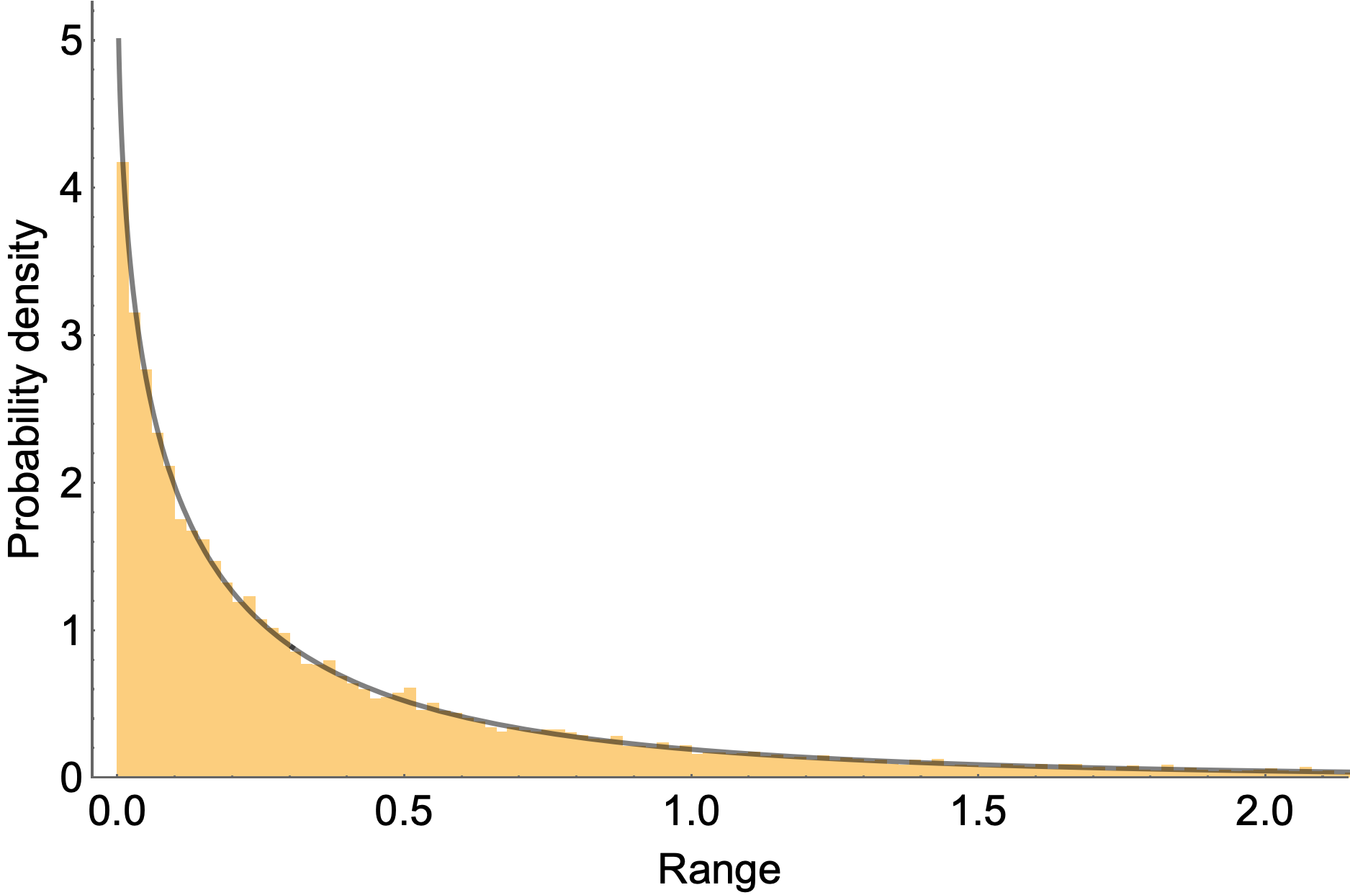
The yellow bars show the frequency density of the sampled ranges, and the black curve shows the prediction according to our result above.
If the problem is about first finding the distribution of water droplets as a function of distance, and then finding the peak of that distribution, then, yes, the peak occurs at r = 0 . However, when a particular water droplet is examined, its most likely speed in which it leaves the nozzle is not 0 , but where the peak of the Poisson distribution occurs, which means its most likely distance it lands is not at r = 0 but somewhere downrange.
This is not to impugn the mathematics of probability theory, this just points out the trouble with language when trying to describe it verbally. What if I were to pose a problem where, given a particular water droplet, what is the most likely distance it will travel? As similiar this sounds compared to the one posted here, it's actually a different question. How do we tell them apart?
Let me illustrate with an example. An unusual casino slot machine pays out as follows, when the lever is activated: Out of 7 times, it randomly delivers
0 in 1 out of 7
1 in 3 out of 7
2 in 2 out of 7
3 in 1 out of 7
The most likely specific payout is 1. But then it delivers the square of the payouts, 0, 1, 4, 9. The most likely specific payout is still 1, after it's been squared. So, but we decide to make up a density plot that ends up looking like this, as a function of the squared payout, to best match the given data:
We can see that the peak density is at squared payout 0. Do we conclude that anyone playing this slot machine is most likely to end up with nothing? I think I would love to keep playing this slot machine.
Transforming the distribution from velocity (v) to range (R) using
F(R)dR = f(v)dv,
where R=(v^2)sin(60°)/g,
gives, F(R)=A.exp(-√R/B), with A and B constants.
which gives R=0 as most likely value, as the function F(R) is maximum at R=0,
Answer, R=0
The relationship between v and r is r = k v 2 , where k = 2 g 3 . Then the c.d.f of r is F r ( u ) = P [ r ≤ u ] = P [ v ≤ k u ] = F v ( k u ) u > 0 where F v is the c.d.f of v . Thus the p.d.f of r is f r ( u ) = F r ′ ( u ) = 2 k u 1 f v ( k u ) = 2 k u 1 × v 0 2 1 k u e − v 0 1 k u = 2 k v 0 2 1 e − v 0 1 k u for u > 0 . Thus f r ( u ) is a decreasing function of u , and so its maximum is achieved at u = 0 .